
Segment Anythingの日本語訳を教えて!
こういった悩みにお答えします.
本記事の信頼性
- リアルタイムシステムの研究歴12年.
- 東大教員の時に,英語でOS(Linuxカーネル)の授業.
- 2012年9月~2013年8月にアメリカのノースカロライナ大学チャペルヒル校(UNC)コンピュータサイエンス学部で客員研究員として勤務.C言語でリアルタイムLinuxの研究開発.
- プログラミング歴15年以上,習得している言語: C/C++,Python,Solidity/Vyper,Java,Ruby,Go,Rust,D,HTML/CSS/JS/PHP,MATLAB,Verse(UEFN), Assembler (x64,aarch64).
- 東大教員の時に,C++言語で開発した「LLVMコンパイラの拡張」,C言語で開発した独自のリアルタイムOS「Mcube Kernel」をGitHubにオープンソースとして公開.
- 2020年1月~現在はアメリカのノースカロライナ州チャペルヒルにあるGuarantee Happiness LLCのCTOとしてECサイト開発やWeb/SNSマーケティングの業務.2022年6月~現在はアメリカのノースカロライナ州チャペルヒルにあるJapanese Tar Heel, Inc.のCEO兼CTO.
- 最近は自然言語処理AIとイーサリアムに関する有益な情報発信や,Unreal Editor for Fortnite(UEFN)でゲーム開発に従事.
- (AI全般を含む)自然言語処理AIの論文の日本語訳や,AIチャットボット(ChatGPT,Auto-GPT,Gemini(旧Bard)など)の記事を50本以上執筆.アメリカのサンフランシスコ(広義のシリコンバレー)の会社でChatGPT/Geminiを訓練するプロンプトエンジニア・マネージャー・Quality Assurance(QA)の業務委託の経験あり.
- (スマートコントラクトのプログラミングを含む)イーサリアムや仮想通貨全般の記事を200本以上執筆.イギリスのロンドンの会社で仮想通貨の英語の記事を日本語に翻訳する業務委託の経験あり.
- UEFNで10本以上のゲームを開発し,フォートナイト上で公開(Fortnite,Fortnite.GG).
こういった私から学べます.
AIのプログラミング言語「C++/Python言語」を学べるおすすめのWebサイトを知りたいあなたはこちらからどうぞ.

独学が難しいあなたは,AIを学べるオンラインプログラミングスクール3社で自分に合うスクールを見つけましょう.後悔はさせません!

国内・海外のAIエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ. こういった悩みにお答えします. こういった私が解説していきます. 国内・海外のAIエンジニアのおすすめ求人サイト(転職エージェント)を紹介します. AIエンジニアになるためには,主にC++/Pytho ... 続きを見る

国内・海外のAIエンジニアのおすすめ求人サイト【転職エージェント】【C++/Python言語】
国内・海外のプロンプトエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ.

Segment Anythingの日本語訳を紹介します.
※図表を含む論文の著作権はSegment Anythingの著者に帰属します.
Meta(旧Facebook)の画像セグメンテーションモデル「Segment Anything Model(SAM)」がわかります.
Segment Anythingの目次は以下になります.
- Abstract
- 1章:Introduction
- 2章:Segment Anything Task
- 3章:Segment Anything Model
- 4章:Segment Anything Data Engine
- 5章:Segment Anything Dataset
- 6章:Segment Anything RAI Analysis
- 7章:Zero-Shot Transfer Experiments
- 8章:Discussion
- References
- 付録A:Segment Anything Model and Task Details
- 付録B:Automatic Mask Generation Details
- 付録C:RAI Additional Details
- 付録D:Experiment Implementation Details
- 付録E:Human Study Experimental Design
- 付録F:Dataset, Annotation, and Model Cards
- 付録G:Annotation Guidelines
Segment Anythingを解説しつつ,私の考えも語ります.
Segment Anythingの概要と私の日本語訳は以下になります.
We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation.
画像セグメンテーションのための新しいタスク,モデル,データセットであるSegment Anything (SA) プロジェクトを紹介する.Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images.
我々の効率的なモデルをデータ収集ループで使用することで,11Mのライセンス画像とプライバシーを尊重した画像に10億以上のマスクを持つ,これまでで(圧倒的に)最大のセグメンテーションデータセットが構築された.The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks.
このモデルは,新しい画像分布やタスクにゼロから移行できるように,プロンプトが出せるように設計・訓練されている.We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results.
多くのタスクでその能力を評価した結果,そのzero-shot性能は印象的であり,しばしば完全教師ありの結果と競合するか,あるいはそれよりも優れていることがわかった.We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
https://arxiv.org/abs/2304.02643
我々は,コンピュータビジョンの基盤モデルの研究を促進するために,Segment Anything Model(SAM)と,1Bマスクと11M画像の対応するデータセット(SA-1B)をhttps://segment-anything.comで公開している.
私の日本語訳の注意点は以下になります.
- 概要は英語と日本語を両方掲載しましたが,本文は私の日本語訳のみを掲載していること(英語で読みたいあなたは原文を読みましょう!)
- 基本的には原文の直訳ですが,わかりにくい箇所は意訳や説明を追加している箇所があること
- 原文の「Acknowledgements」(謝辞)は省略していること
- 本文中に登場する表記「[10]」などは参考文献ですので,興味がある方は本記事の参考文献を参照されたいこと
それでは,Segment Anythingの本文を読みすすめましょう!
目次
- 1 1章:Introduction(はじめに)
- 2 2章:Segment Anything Task(Segment Anythingタスク)
- 3 3章:Segment Anything Model
- 4 4章:Segment Anything Data Engine(Segment Anythingデータエンジン)
- 5 5章:Segment Anything Dataset(Segment Anythingデータセット)
- 6 6章:Segment Anything RAI Analysis(Segment Anything RAI分析)
- 7 7章:Zero-Shot Transfer Experiments(Zero-Shot Transferの実験)
- 7.1 7.1節:Zero-Shot Single Point Valid Mask Evaluation(Zero-Shot Point有効マスク評価)
- 7.2 7.2節:Zero-Shot Edge Detection(Zero-Shotエッジ検出)
- 7.3 7.3節:Zero-Shot Object Proposals(Zero-Shotオブジェクト提案)
- 7.4 7.4節:Zero-Shot Instance Segmentation(Zero-Shotインスタンスセグメンテーション)
- 7.5 7.5節:Zero-Shot Text-to-Mask
- 7.6 7.6節:Ablations(アブレーション)
- 8 8章:Discussion(ディスカッション)
- 9 References(参考文献)
- 10 付録A:Segment Anything Model and Task Details(Segment Anything Modelとタスク詳細)
- 11 付録B:Automatic Mask Generation Details(自動マスク生成の詳細)
- 12 付録C:RAI Additional Details(RAI追加情報)
- 13 付録D:Experiment Implementation Details(実験の実装の詳細)
- 13.1 付録D.1:Zero-Shot Single Point Valid Mask Evaluation(Zero-Shotシングルポイント有効マスク評価)
- 13.2 付録D.2:Zero-Shot Edge Detection(Zero-Shotエッジ検出)
- 13.3 付録D.3:Zero-Shot Object Proposals(Zero-Shotオブジェクト提案)
- 13.4 付録D.4:Zero-Shot Instance Segmentation(Zero-Shotインスタンスセグメンテーション)
- 13.5 付録D.5:Zero-Shot Text-to-Mask
- 13.6 付録D.6:Probing the Latent Space of SAM(SAMの潜伏空間を探る)
- 14 付録E:Human Study Experimental Design(ヒト試験の実験デザイン)
- 15 付録F:Dataset, Annotation, and Model Cards(データセット,アノテーション,モデルカード)
- 16 付録G:Annotation Guidelines(アノテーションガイドライン)
- 17 参考:Segment Anythingの解説スライド・動画
- 18 まとめ
1章:Introduction(はじめに)
ウェブスケールのデータセットで事前に訓練された大規模な言語モデルは,強力なzero-shotおよびfew-shotの汎化によって,NLPに革命をもたらしている[10].
これらの「基盤モデル」[8]は,訓練中に見た以上のタスクやデータ分布に汎化することができる.
この機能はプロンプトエンジニアリングで実装されることが多く,手作業で作成したテキストを使用して,言語モデルが目の前のタスクに対して有効なテキスト応答を生成するように促す.
Web上の豊富なテキストコーパスを用いてスケールアップして訓練した場合,これらのモデルのzero-shotとfew-shotの性能は,ファインチューニングされたモデル[10, 21]と驚くほどよく比較される(場合によっては一致することもある).
経験的な傾向として,この挙動はモデルの規模,データセットのサイズ,および訓練の総計算量に応じて改善される[56, 10, 21, 51].
コンピュータビジョンの分野でも,その程度は低いものの,基盤モデルが研究されている.
最も顕著な例は,ウェブ上のテキストと画像のペアリングである.
例えば,CLIP[82]とALIGN[55]は,コントラスト学習を利用して,2つのモダリティを揃えるテキストと画像のエンコーダを学習させる.
一度訓練されたテキストプロンプトは,新しい視覚的概念やデータ分布にzero-shotで汎化することができる.
また,このようなエンコーダは,他のモジュールと効果的に組み合わせて,画像生成などの下流のタスクを可能にする(例:DALL-E[83]).
視覚と言語エンコーダについては多くの進歩が見られるが,コンピュータビジョンにはこの範囲を超えた幅広い問題があり,その多くでは豊富な学習データが存在しない.
本研究では,画像セグメンテーションのための基盤モデルを構築することを目標とする.
すなわち,プロンプトエンジニアリング可能なモデルを開発し,強力な汎化を可能にするタスクを用いた幅広いデータセットで事前訓練させることを目指す.
このモデルにより,プロンプトエンジニアリングを用いて,新しいデータ分布における下流の様々なセグメンテーション問題を解決することを目的とする.
この計画の成功は,タスク,モデル,データという3つの要素にかかっている.
それらを開発するために,我々は画像分割に関する以下のような疑問に取り組む.
- zero-shot汎化を可能にするタスクとは?
- 対応するモデルアーキテクチャは何か?
- このタスクとモデルを動かすことができるデータは何か?
これらの問題は複雑に絡み合っており,包括的な解決策が必要である.
我々は,強力な前訓練の目的を提供し,幅広い下流のアプリケーションを可能にするために,十分に一般的であるプロンプト可能なセグメンテーションタスクを定義することから始める.
このタスクでは,柔軟なプロンプトをサポートし,対話的な使用を可能にするために,プロンプト時にリアルタイムでセグメンテーションマスクを出力できるモデルが必要である.
モデルを訓練するためには,多様で大規模なデータソースが必要である.
残念ながら,セグメンテーションのためのウェブスケールのデータソースは存在しない.
これを解決するために,我々は「データエンジン」を構築した.
すなわち,データ収集を支援するために効率的なモデルを使用し,モデルを改善するために新たに収集したデータを使用するということを繰り返す.
次に,相互接続された各コンポーネントを紹介し,作成したデータセットと我々のアプローチの有効性を実証する実験を行う.
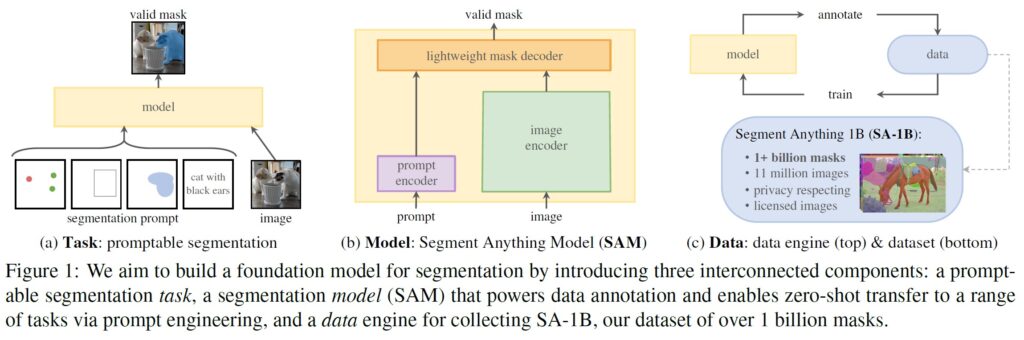
(a)タスク:プロンプトセグメンテーション,(b)モデル:Segment Anything Model (SAM),(c)データ:データエンジン(上部),データセット(下部)
タスク(2章):
NLP や最近ではコンピュータビジョンにおいて,基盤モデルは,しばしば「プロンプト」技法を用いることで,新しいデータセットやタスクに対してzero-shotやfew-shotの学習を実行できる有望な開発である.
このような研究に触発され,我々はプロンプト可能なセグメンテーションタスクを提案する.
このタスクの目標は,任意のセグメンテーションプロンプトが与えられたときに,有効なセグメンテーションマスクを返すことである(図1a参照).
プロンプトとは,画像内の何をセグメンテーションするかを指定するもので,例えば,オブジェクトを特定する空間情報やテキスト情報をプロンプトに含めることができる.
有効な出力マスクの要件は,プロンプトが曖昧で複数のオブジェクトを指す可能性がある場合でも(例:シャツ上のポイントはシャツまたはそれを着ている人のいずれかを示す),出力はこれらのオブジェクトの少なくとも1つの妥当なマスクでなければならないことを意味する.
我々は,プロンプトを用いたセグメンテーションタスクを,事前訓練の目的として,またプロンプトエンジニアリングによって一般的な下流のセグメンテーションタスクを解決するために使用する.
モデル(3章):
プロンプトを表示できるセグメンテーションタスクと実世界での使用という目標が,モデルアーキテクチャに制約を課している.
特に,モデルは柔軟なプロンプトをサポートする必要があり,対話的な使用を可能にするために償却されたリアルタイムでマスクを計算する必要があり,曖昧性を認識する必要がある.
驚くべきことに,シンプルな設計で3つの制約をすべて満たせることがわかった.
すなわち,強力な画像エンコーダが画像埋め込みを計算し,プロンプトエンコーダがプロンプトを埋め込み,そして2つの情報源をセグメンテーションマスクを予測する軽量マスクデコーダに結合させる.
このモデルをSegment Anything Model,すなわちSAMと呼ぶ(図1b参照).
SAMを画像エンコーダと高速プロンプトエンコーダ/マスクデコーダに分離することで,同じ画像埋め込みを異なるプロンプトで再利用(コスト償却)できる.
プロンプトエンコーダとマスクデコーダは,画像埋め込みがあれば,ウェブブラウザ上でプロンプトからマスクを50ミリ秒以下で予測する.
我々は,ポイント,ボックス,マスクのプロンプトに焦点を当て,自由形式のテキストプロンプトを用いた初期結果も示す.
SAMを曖昧性に対応させるため,1つのプロンプトに対して複数のマスクを予測するように設計し,シャツと人の例のような曖昧性をSAMが自然に扱えるようにした.
データエンジン(4章):
新しいデータ分布に対する強力な汎化を実現するためには,既に存在するセグメンテーションデータセットを超えて,大規模かつ多様なマスクセットでSAMを訓練する必要があることがわかった.
基盤モデルの典型的なアプローチはオンラインでデータを入手することであるが[82],マスクは自然に豊富にあるわけではないので,別の戦略が必要である.
我々のソリューションは,「データエンジン」を構築することである.
つまり,モデルインザループのデータセットアノテーションと我々のモデルを共同開発することである(図1c参照).
我々のデータエンジンは,アシストマニュアル,セミオート,フルオートの3つのステージがある.
第1段階では,SAMは,古典的な対話型セグメンテーションの設定と同様に,アノテーターがマスクにアノテーションするのを支援する.
第2段階では,SAMがオブジェクトの位置を命令することで,オブジェクトのサブセットに対するマスクを自動生成し,アノテータは残りのオブジェクトのアノテーションに集中することで,マスクの多様性を高めることができる.
最終段階では,SAMに規則的なフォアグラウンドポイントのグリッドを与えることで,1画像あたり平均100個以内の高品質マスクを生成する.

データセット(5章):
我々の最終データセットであるSA-1Bは,11Mのライセンスされたプライバシー保護された画像から1B以上のマスクを含む(図2参照).
SA-1Bは,我々のデータエンジンの最終段階を使用して完全に自動で収集され,既存のセグメンテーションデータセット[66, 44, 117, 60]の400倍以上のマスクがあり,我々が広範囲に検証した結果,マスクは高品質で多様であることがわかった.
SA-1Bは,SAMを堅牢で一般的なものにするための訓練に利用するだけでなく,新しい基盤モデルの構築を目指す研究にとって貴重なリソースとなることを期待している.
責任あるAI(6章):
SA-1BとSAMを使用する際の潜在的な公平性の懸念とバイアスについて研究し,報告している.
SA-1Bの画像は地理的,経済的に多様な国々にまたがっており,SAMは異なるグループの人々に対して同様の性能を発揮することがわかった.
合わせて,実際のユースケースにおいて,我々の研究がより公平なものになることを期待している.
付録として,モデルとデータセットのカードを提供する.
実験(7章):
我々はSAMを広範囲に評価した.
まず,23のセグメンテーションデータセットの多様な新しいスイートを用いて,SAMは単一のフォアグラウンドポイントから高品質のマスクを生成し,多くの場合,手動でアノテーションしたグランドトゥルースのマスクをわずかに下回る程度であることがわかった.
第2に,プロンプトエンジニアリングによるzero-shot転送プロトコルにおいて,エッジ検出,オブジェクト提案生成,インスタンス分割,テキストからマスク(text-to-mask)への予測の予備調査など,さまざまな下流タスクで一貫して強力な定量的・定性的結果を得ることができた.
これらの結果は,SAMをプロンプトエンジニアリングと併用することで,SAMの学習データ以外のオブジェクトや画像の分布を含む様々なタスクを解決できることを示唆している.
とはいえ,8章で述べるように,改善の余地が残されている.
リリース:
研究用にSA-1Bデータセットを公開し,SAMを寛容なオープンライセンス(Apache 2.0)のもとで公開する(https://segment-anything.com).
また,オンラインデモでSAMの機能を紹介している.
2章:Segment Anything Task(Segment Anythingタスク)
我々は,次のトークンを予測するタスクが基盤モデルの事前訓練に使用され,プロンプトエンジニアリングによって多様な下流タスクを解決する,NLPからインスピレーションを得ている[10].
セグメンテーションのための基盤モデルを構築するために,我々は類似の機能を持つタスクを定義することを目指す.

図3:各列は,1つの曖昧なポイントプロンプト(緑の丸)からSAMが生成した3つの有効なマスクを示す.
タスク:
まず,プロンプトのアイデアをNLPからセグメンテーションに翻訳することから始める.
プロンプトとは,フォアグラウンド/バックグラウンドのポイントのセット,大まかなボックスやマスク,自由形式のテキスト,または一般的に,画像の何を分割するかを示すあらゆる情報である.
プロンプトセグメンテーションのタスクは,任意のプロンプトに対して有効なセグメンテーションマスクを返すことである.
「有効な」マスクという要件は,プロンプトが曖昧で複数のオブジェクトを指す可能性がある場合でも(例:シャツと人の例の図3を参照),そのオブジェクトの少なくとも1つに対する妥当なマスクを出力する必要があるということである.
この要件は,言語モデルが曖昧なプロンプトに対して首尾一貫した応答を出力することを期待するのと同様である.
このタスクを選んだのは,自然な事前訓練アルゴリズムと,プロンプトによって下流のセグメンテーションタスクにzero-shotで転送するための一般的な方法につながるからである.
事前訓練:
プロンプトセグメンテーションのタスクは,各訓練サンプルのプロンプト(ポイント,ボックス,マスクなど)のシーケンスをシミュレートし,モデルのマスク予測をグランドトゥルースと比較する自然な事前訓練アルゴリズムを示唆している.
我々はこの方法を対話型セグメンテーション[109, 70]から適応させる.
しかし,十分なユーザ入力の後に最終的に有効なマスクを予測することを目的とする対話型セグメンテーションとは異なり,我々の目的は,プロンプトが曖昧であっても,どのプロンプトに対しても常に有効なマスクを予測することである.
これにより,事前に訓練されたモデルは,データエンジンの4章で必要とされる自動アノテーションを含む,曖昧性を伴うユースケースで有効であることが保証される.
このタスクをうまくこなすことは困難であり,特殊なモデリングと訓練ロスの選択が必要であることに留意し,3章で説明する.
zero-shot転送:
直感的には,事前訓練により,推論時にどのようなプロンプトに対しても適切に応答する能力をモデルに付与する.
適切なプロンプトを設計することにより,下流のタスクを解決することができる.
例えば,猫のバウンディングボックス検出器がある場合,その検出器のボックス出力をモデルにプロンプトとして与えることで,猫のインスタンス分割を解決することができる.
一般に,実用的なセグメンテーションのタスクは,プロンプトとして提供されることが多い.
データセットの自動ラベリングに加え,7章では,5つの多様なタスクの例について実験している.
関連研究:
セグメンテーションは広い分野である.
インタラクティブセグメンテーション[57, 109],エッジ検出[3],超ピクセル化 [85],オブジェクト提案生成[2],フォアグラウンドセグメンテーション[94],セマンティックセグメンテーション[90],インスタンスセグメンテーション[66],パノプティックセグメンテーション[59]などである.
プロンプトエンジニアリングによって,多くの既存および新規のセグメンテーションタスクに適応できる(すべてではないが),広範な能力を持つモデルを作成することが,プロンプト可能なセグメンテーションタスクの目標である.
この能力は,タスクの汎化[26]の一形態である.
これは,マルチタスクセグメンテーションシステムに関する従来の研究とは異なることに注意されたい.
マルチタスクシステムでは,1つのモデルが,例えば,セマンティック,インスタンス,およびパノプティックセグメンテーション[114, 19, 54]のような,決まったタスクセットを実行するが,訓練およびテストタスクは同じである.
我々の研究における重要な違いは,プロンプトセグメンテーションのために訓練されたモデルは,より大きなシステムのコンポーネントとして動作することにより,推論時に新しい別のタスクを実行できることである.
例えば,インスタンスセグメンテーションを実行するために,プロンプトセグメンテーションモデルを既存のオブジェクト検出器と結合する.
ディスカッション:
プロンプトとコンポジションは,単一のモデルを拡張可能な方法で使用することを可能にする強力なツールであり,モデル設計時に未知のタスクを達成する可能性がある.
このアプローチは,例えば,CLIP[82]がDALL-E[83]画像生成システムのtext-imageアラインメントコンポーネントであるように,他の基盤モデルがどのように使用されるかに類似している.
プロンプトエンジニアリングのような技術を駆使したコンポーザブルなシステム設計により,固定されたタスクのために特別に訓練されたシステムよりも,より多様なアプリケーションを実現できるようになると予想している.
また,プロンプトエンジニアリングとインタラクティブセグメンテーションを,コンポジションというレンズを通して比較することも興味深い.
インタラクティブなセグメンテーションモデルは,人間のユーザを念頭に置いて設計されているが,プロンプト可能なセグメンテーションのために訓練されたモデルは,より大きなアルゴリズムシステムに構成することも可能であることを示す.
3章:Segment Anything Model
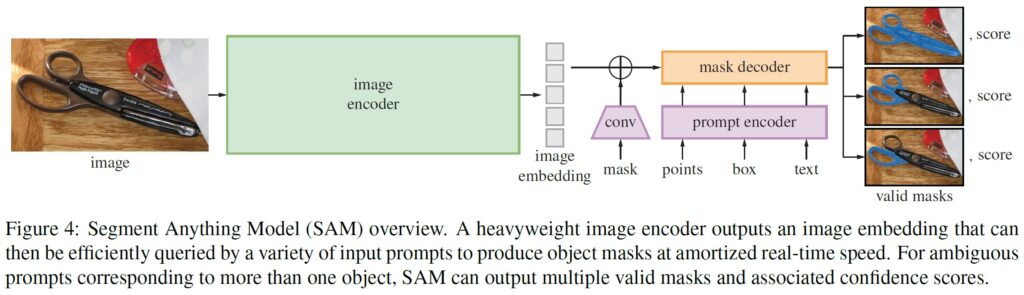
次に,プロンプトセグメンテーションのためのSegment Anything Model(SAM)を説明する.
SAMは,図4に示すように,3つのコンポーネント(画像エンコーダ,柔軟なプロンプトエンコーダ,高速マスクデコーダ)から構成されている.
SAMは,Transformerビジョンモデル[14, 33, 20, 62]をベースに,(償却された)リアルタイム性能のための特定のトレードオフを設定している.
ここでは,これらのコンポーネントを高レベルで説明し,詳細は付録Aで説明する.
画像エンコーダ:
スケーラビリティと強力な事前訓練手法に動機づけられ,高解像度入力の処理に最小限の適応をしたMAE[47]事前訓練済みVision Transformer(ViT)[33]を使用している[62].
画像エンコーダは画像ごとに1回実行され,モデルを促す前に適用することができる.
プロンプトエンコーダ:
プロンプトは,疎(ポイント,ボックス,テキスト)と密(マスク)の2つのセットで考える.
ポイントとボックスは位置エンコーディング[95]で表現し,プロンプトタイプごとに学習した埋め込みと合計し,自由形式のテキストはCLIP[82]の既製のテキストエンコーダで表現する.
密なプロンプト(すなわちマスク)は,畳み込みを使って埋め込まれ,画像埋め込みと要素ごとに合計される.
マスクデコーダ:
マスクデコーダは,画像埋め込み,プロンプト埋め込み,および出力トークンを効率的にマスクにマッピングする.
この設計は,[14, 20]に触発され,Transformerデコーダブロック[103]の修正と,動的マスク予測ヘッドを採用している.
我々の修正したデコーダブロックは,すべての埋め込みを更新するために,プロンプトのセルフアテンションと2方向のクロスアテンション(プロンプトから画像埋め込み,またはその逆)を使用する.
2つのブロックを実行した後,画像埋め込みをアップサンプリングし,MLPが出力トークンを動的線形分類器にマッピングし,各画像位置でのマスクフォアグラウンド確率を計算する.
曖昧性の解消:
1つの出力で,曖昧なプロンプトが与えられた場合,モデルは複数の有効なマスクを平均化する.
そこで,1つのプロンプトに対して複数のマスク出力を予測するようにモデルを修正する(図3参照).
3つのマスク出力は,ほとんどの一般的なケースに対応するのに十分であることがわかった(ネストしたマスクは,多くの場合,最大で3つの深さ:全体,部分,サブパート).
訓練中,マスクに対する最小損失[15, 45, 64]のみをバックプロップする.
マスクをランク付けするために,モデルは各マスクの信頼度スコア(すなわち,推定IoU)を予測する.
効率性:
全体的なモデル設計は,主に効率性を重視している.
事前に計算された画像埋め込みがあれば,プロンプトエンコーダとマスクデコーダは,ウェブブラウザ上でCPUにより,50ms以内で実行される.
この実行性能により,本モデルのシームレスでリアルタイムの対話型プロンプトが可能になる.
損失(ロス)と訓練:
[14]で使用されたフォーカルロス[65]とダイスロス[73]の線形結合でマスク予測をスーパーバイズしている.
幾何学的なプロンプト(テキストプロンプトについては7.5節参照)を組み合わせて,プロンプト可能なセグメンテーションタスクの訓練を行う.
[92, 37]に従い,1マスクあたり11ラウンドでプロンプトをランダムにサンプリングすることで対話型の設定をシミュレートし,SAMがデータエンジンにシームレスに統合できるようにする.
4章:Segment Anything Data Engine(Segment Anythingデータエンジン)
セグメンテーションマスクはインターネット上に豊富に存在しないため,我々は1.1BのマスクデータセットSA-1Bを収集できるようにデータエンジンを構築した.
このデータエンジンは,以下の3段階からなる.
- モデルアシストによるマニュアルアノテーションステージ(アシストマニュアルステージ)
- 自動予測マスクとモデルによるアノテーションを組み合わせたセミオートマチックステージ
- アノテータの入力なしにモデルがマスクを生成するフルオートマチックステージ
次に,それぞれの詳細について説明する.
アシストマニュアルステージ:
第1段階では,古典的な対話型セグメンテーションに似た,プロのアノテータチームが,SAMを搭載したブラウザベースの対話型セグメンテーションツールを使って,フォアグラウンド/バックグラウンドのオブジェクトポイントをクリックしてマスクにラベル付けする.
マスクは,ピクセル単位の「ブラシ」と「消しゴム」ツールでファインチューニングすることができる.
モデルアシスト型アノテーションは,ブラウザ上で直接リアルタイムに実行され(事前に計算された画像埋め込みを使用),真のインタラクティブな体験を提供する.
オブジェクトのラベル付けには意味的な制約を設けず,アノテータは「もの」と「こと」の両方に自由にラベル付けを行う[1].
アノテータには,名前や説明のできるオブジェクトにラベルを付けることを提案したが,名前や説明を収集しなかった.
アノテータは,目立つものから順にラベルを貼るように命令され,1つのマスクのアノテーションに30秒以上かかる場合は,次の画像に進むように促された.
この段階では,一般的な公開セグメンテーションデータセットを用いてSAMを訓練させた.
十分なデータアノテーションを行った後,新たにアノテーションされたマスクのみを用いてSAMを再訓練した.
より多くのマスクを収集するにつれ,画像エンコーダはViT-BからViT-Hにスケールアップされ,その他のアーキテクチャの詳細が進化した.
合計で6回,モデルの再訓練を行った.
モデルの改良に伴い,1マスクあたりの平均アノテーション時間は34秒から14秒に短縮された.
14秒という時間は,COCO[66]のマスクアノテーションの6.5倍であり,極限点を用いたバウンディングボックスラベリング[76, 71]の2倍しか遅くないことに注意されたい.
SAMの改良に伴い,画像1枚あたりの平均マスク数は20枚から44枚に増加した.
全体として,この段階で120k枚の画像から4.3M枚のマスクを収集した.
セミオートマチックステージ:
この段階では,マスクの多様性を高めることで,あらゆるものをセグメンテーションするモデルの能力を向上させることを目的とした.
まず,あまり目立たない対象物にアノテーションを集中させるために,自信のあるマスクを自動的に検出した.
そして,これらのマスクをあらかじめ塗りつぶした画像をアノテーション担当者に提示し,アノテーションされていないオブジェクトがあれば追加でアノテーションするよう依頼した.
確信犯的なマスクを検出するために,一般的な「オブジェクト」カテゴリを使用して,すべての第1段階のマスクに対してバウンディングボックス検出器[84]を訓練した.
この段階で,180k枚の画像から5.9M枚のマスクを追加で収集した(合計10.2M枚のマスクがある).
第1段階と同様に,新たに収集したデータに対して定期的に(5回)モデルの再訓練を行った.
これらのオブジェクトはラベル付けがより困難であったため,1マスクあたりの平均アノテーション時間は34秒に戻った(自動マスクを除く).
画像1枚あたりの平均マスク数は44枚から72枚になった(自動マスクを含む).
フルオートマチックステージ:
最終段階では,アノテーションは完全に自動化された.
これが実現できたのは,我々のモデルに2つの大きな改良が加えられたからである.
まず,このステージの開始時点で,前ステージの多様なマスクを含め,モデルを大幅に改善するのに十分な量のマスクを収集した.
第2に,この段階までに曖昧性を意識したモデルを開発し,曖昧なケースでも有効なマスクを予測できるようにした.
具体的には,32x32の規則正しい格子状のポイントをモデルに促し,各ポイントに対して有効なオブジェクトに対応する可能性があるマスクの集合を予測した.
曖昧性を考慮したモデルでは,あるポイントが部品やサブパーツの上にある場合,我々のモデルはサブパーツ,パーツ,そして全体のオブジェクトを返す.
また,本モデルのIoU予測モジュールは,自信のあるマスクを選択するために使用される.
さらに,安定したマスクのみを抽出した(確率マップを\(0.5 - \delta\)と\(0.5 + \delta\)で閾値処理した結果,同様のマスクが得られた場合,安定したマスクとみなす).
最後に,自信のある安定したマスクを選択した後,非最大限の抑制(NMS:Non-Maximal Suppression)を適用し,重複をフィルタリングした.
小さなマスクの品質をさらに向上させるために,複数の重なり合うズームイン画像の切り出しも処理した.
この段階の詳細については,付録Bを参照.
データセットの全11M画像に完全自動マスク生成を適用し,合計1.1B個の高品質マスクを生成した.
次に,得られたデータセットであるSA-1Bについて説明し,分析する.
5章:Segment Anything Dataset(Segment Anythingデータセット)
我々のデータセットであるSA-1Bは,11M枚の多様な高解像度画像と,我々のデータエンジンで収集された1.1B枚の高品質セグメンテーションマスクで構成されている.
SA-1Bを既存のデータセットと比較し,マスクの品質と特性を分析する.
SA-1Bは,将来のコンピュータビジョンの基盤モデルの開発に役立てるために公開するものである.
SA-1Bは,特定の研究用途のために有利なライセンス契約の下で公開され,研究者のための保護がなされていることに注意されたい.
画像:
写真家と直接取引するプロバイダーから,新たに11Mの画像セットのライセンスを取得した.
これらの画像は高解像度(平均3300x4950ピクセル)であり,その結果,データサイズが大きくなり,アクセスや保存に問題が生じる可能性がある.
そこで,最短辺を1500ピクセルに設定し,ダウンサンプリングした画像を公開する.
ダウンサンプリング後も,既存の多くのビジョンデータセット(例:COCO[66]の画像は480x640ピクセル以下)よりもかなり高い解像度を有している.
今日,ほとんどのモデルは,もっと低い解像度の入力で動作していることに注意されたい.
公開された画像は,顔や車のナンバープレートがぼかされている.
マスク:
我々のデータエンジンは1.1B個のマスクを生成し,その99.1%は完全自動生成した.
したがって,自動生成されたマスクの品質が中心的に重要である.
我々はそれらをプロのアノテーションと直接比較し,様々なマスクの特性が著名なセグメンテーションデータセットとどのように比較されるかを見ている.
以下の分析および7章の実験に見られるように,我々の主な結論は,我々の自動マスクが高品質でモデルの訓練に有効である.
この結果を受けて,SA-1Bでは自動生成されたマスクのみを搭載している.
マスクの品質:
マスクの品質を評価するために,500枚の画像(50k個以下のマスク)をランダムに抽出し,プロのアノテータにこれらの画像内のすべてのマスクの品質を改善するように依頼した.
アノテータは,当社のモデルやピクセル精度の高い「ブラシ」と「消しゴム」編集ツールを使って,この作業を行った.
この手順により,自動的に予測されたマスクとプロの手によって修正されたマスクのペアができあがった.
各ペア間のIoUを計算したところ,94%のペアが90%以上のIoU(97%のペアは75%以上のIoU)であることがわかった.
比較のため,先行研究では,アノテータ間の整合性を85~91%のIoUと見積もっている[44, 60].
7章の実験では,マスクの品質が様々なデータセットに対して高いこと,自動マスクでモデルを訓練すると,データエンジンが生成したすべてのマスクを使用するのとほぼ同等であることが,人間の評価によって確認された.
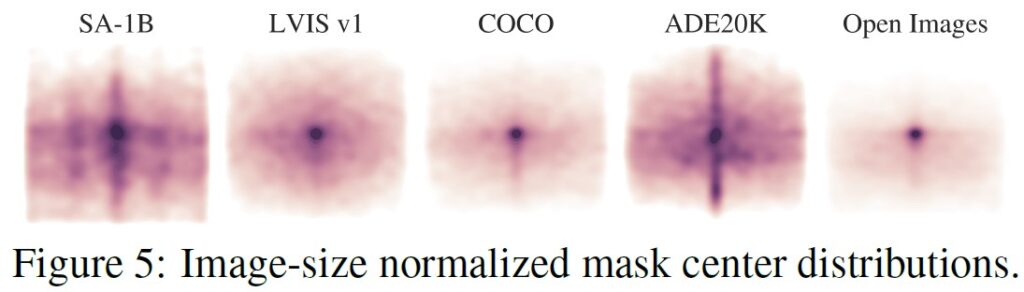
マスクの性質:
図5では,SA-1Bのオブジェクト中心の空間分布を,既存の最大のセグメンテーションデータセットと比較してプロットしている.
すべてのデータセットで,共通の撮影者のバイアスが存在する.
最も類似した分布を持つLVIS v1[44]とADE20K[117]と比較すると,SA-1Bは画像の隅々までカバーしており,COCO[66]とOpen Images V5[60] はより顕著な中心のバイアスがあることがわかる.
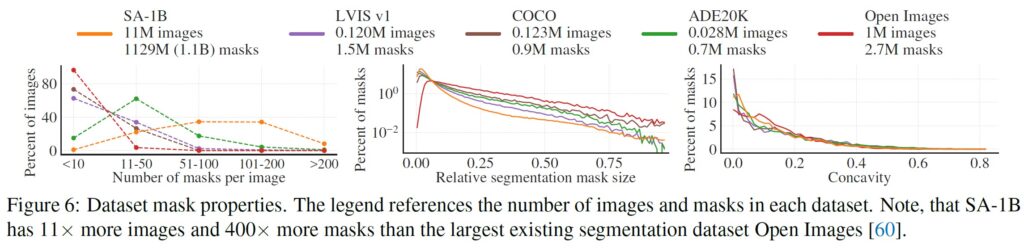
図6(凡例)では,これらのデータセットをサイズ別に比較している.
SA-1Bは,2番目に大きいOpen Imagesと比較して,画像数が11倍以上,マスク数が400倍以上となっている.
平均すると,Open Imagesよりも1画像あたり36倍以上の多くのマスクを持っている.
このポイントで最も近いデータセットであるADE20Kは,それでも1画像あたりのマスク数が3.5倍以下で少ない.
図6(左)は,1画像あたりのマスク数の分布をプロットしたものである.
次に,画像とマスクの大きさ(マスク面積の平方根を画像面積で割ったもの)を図6(中)で見てみる.
予想通り,本データセットは画像あたりのマスク数が多いため,相対的にサイズの小さいマスクや中程度のマスクの割合も多くなる傾向がある.
最後に,形状の複雑さを分析するために,図6(右)のマスクの凹み度(1マイナスマスク面積÷マスクの凸包の面積)を見てみる.
形状の複雑さはマスクサイズと相関があるため,まずマスクサイズをビンにしたものから層別サンプリングを行い,データセットのマスクサイズ分布を制御する.
その結果,今回のマスクの凹み分布は,他のデータセットとほぼ同じであることが確認された.
6章:Segment Anything RAI Analysis(Segment Anything RAI分析)
次に,SA-1BとSAMを使用する際の潜在的な公平性の懸念や偏りを調査することで,我々の研究の責任あるAI(RAI:Responsible AI)分析を実施する.
我々は,SA-1Bの地理的および所得分布と,人々の保護された属性にわたるSAMの公平性に焦点を当てる.
また,付録Fでデータセット,データアノテーション,モデルカードを提供する.
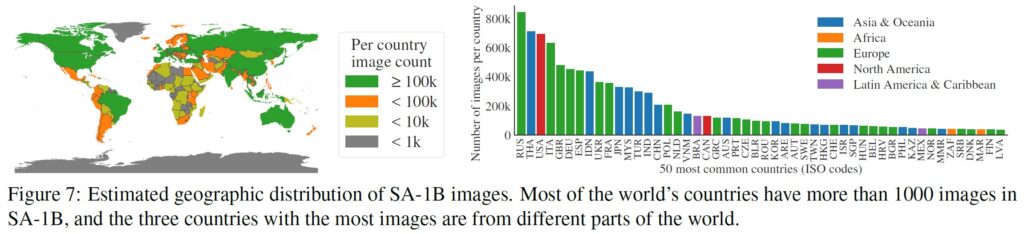
地理的・所得的表現:
標準的な方法(付録C参照)を用いて,画像が撮影された国を推定する.
図7では,SA-1Bの国ごとの画像数(左)と,最も画像の多い50カ国(右)を可視化している.
上位3カ国は世界の異なる地域から集まっていることに注意されたい.
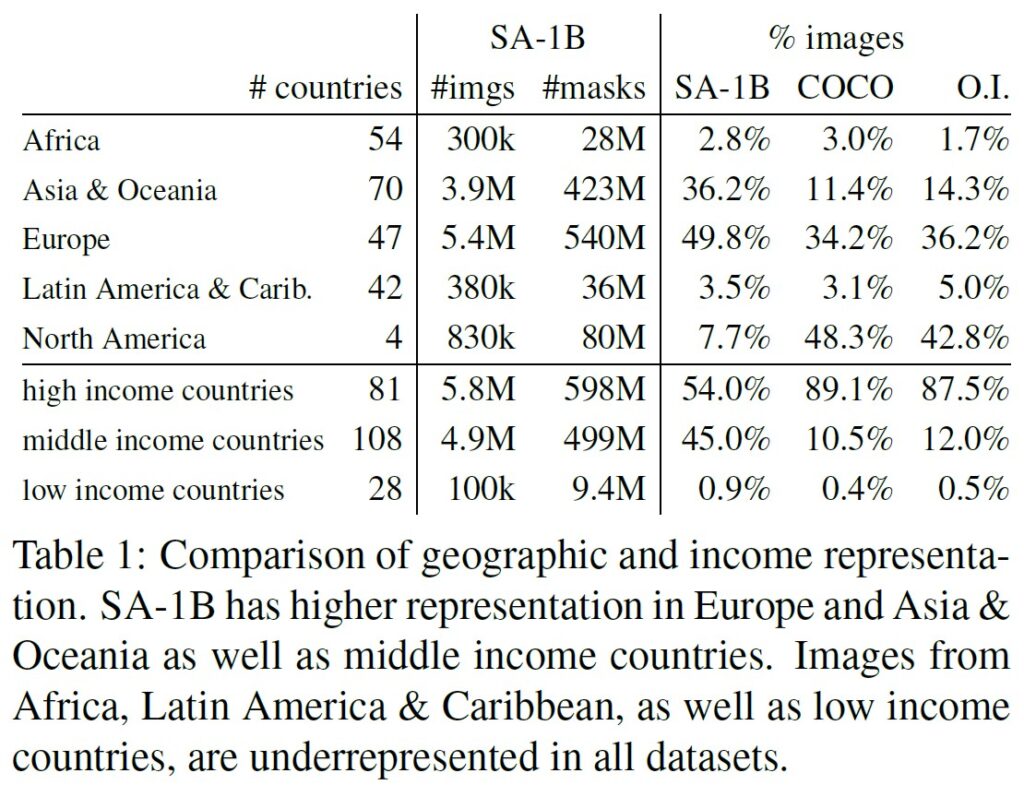
次に,表1では,SA-1B,COCO[66],Open Images[60]の地理的・所得的表現を比較している.
SA-1Bは,ヨーロッパ,アジア・オセアニア,および中所得国の画像の割合が大幅に高くなっている.
すべてのデータセットで,アフリカと低所得国の割合が低い.
SA-1Bでは,アフリカを含むすべての地域で,少なくとも2800万個のマスクがあり,これまでのデータセットの総マスク数の10倍以上であることに注意されたい.
最後に,画像1枚あたりの平均マスク数(図示せず)は,地域や所得によってかなり一貫している(画像1枚あたり94~108枚)ことを確認した.

セグメント化した人の公平性:
我々は,グループ間のSAMの性能の不一致を測定することにより,知覚された性別表示,知覚された年齢層,知覚された肌色における潜在的な公平性の懸念を調査する.
性別と年齢についてはMore Inclusive Annotations for People(MIAP)[87]のデータセットを,肌色については独自のデータセットを使用する(付録C参照).
評価は,1ポイントと3ポイントのランダムサンプリングによる対話型セグメンテーションのシミュレーションを使用する(付録D参照).
表2(左上)は,知覚された性別の表示についての結果である.
検出とセグメンテーションのデータセットでは,女性の割合が低いことが示されていることに注意する必要がある[115]が,SAMはグループ間で同様の性能を示すことが確認された.
表2(左下)では,知覚される年齢に関する分析を繰り返し,大規模なデータセット[110]では,若いと知覚される人や年配の人が過小評価されることが示されていることに注意されたい.
SAMは,(信頼区間は大きいが)年上と思われる人たちに対して最も良い結果を示した.
最後に,表2(右)の知覚された肌の色についての分析を繰り返すが,大規模なデータセットでは,見た目の肌の色が明るい人は過剰に表現され,肌の色が暗い人は過小に表現されることに注意されたい[110].
MIAPには肌色のアノテーションが含まれていないため,我々は,1(最も明るい肌色)から6(最も暗い肌色)までのフィッツパトリックのスキンタイプ[36]のアノテーションを含む独自のデータセットを用いている.
平均値は多少異なるものの,グループ間で有意な差は認めらなかった.
この結果は,タスクの性質に起因するものであり,SAMが大規模なシステムのコンポーネントとして使用される場合に,バイアスが生じる可能性があることを認識している,と我々は考えている.
最後に,付録Cでは,衣服のセグメンテーションに分析を拡張し,知覚された性別の表示によるバイアスの兆候を発見した.
7章:Zero-Shot Transfer Experiments(Zero-Shot Transferの実験)

本章では,Segment Anything Model(SAM)のzero-shot transfer実験を紹介する.
5つのタスクを検討し,そのうち4つは,SAMの訓練に使用したプロンプトセグメンテーションタスクとは大きく異なるタスクである.
これらの実験では,訓練中に見られなかったデータセットとタスクでSAMを評価する(「zero-shot transfer」の用法は,CLIP[82]における用法に従う).
データセットには,水中や自我中心の画像(図8など)など,我々の知る限りではSA-1Bには登場しない新しい画像分布が含まれる可能性がある.
この実験では,プロンプトセグメンテーションの中核的な目標である,「どんなプロンプトからも有効なマスクを生成することをテストすること」から始める.
フォアグラウンドのポイントプロンプトは,他のより具体的なプロンプトよりも曖昧である可能性が高いため,困難なシナリオであることを強調している.
次に,低レベル,中レベル,高レベルの画像理解を横断する一連の実験を紹介し,この分野の歴史的な発展とほぼ平行する.
具体的には,(1)エッジ検出,(2)オブジェクト提案生成,(3)インスタンス分割,(4)概念実証として自由形式のテキストからのオブジェクト分割をSAMに命令する.
これらの4つのタスクは,SAMが訓練したプロンプトセグメンテーションタスクとは大きく異なり,プロンプトエンジニアリングによって実装されている.
我々の実験は,アブレーション実験で締めくくられる.
実装:
特に指定がない限り,(1)SAMはMAE [47] で事前訓練されたViT-H[33]画像エンコーダを使用し,(2)SAMはSA-1Bで学習され,このデータセットには我々のデータエンジンの最終段階から自動生成されたマスクのみが含まれていることに注意されたい.
ハイパーパラメータなど,その他のモデルや訓練の詳細については,付録Aを参照されたい.
7.1節:Zero-Shot Single Point Valid Mask Evaluation(Zero-Shot Point有効マスク評価)
タスク:
1つのフォアグラウンドポイントからオブジェクトをセグメンテーションすることを評価する.
このタスクは,1つのポイントが複数のオブジェクトを参照することができるため,不向きである.
ほとんどのデータセットでは,グラウンドトゥルースマスクが可能なマスクをすべて列挙しているわけではないので,自動測定基準の信頼性が低くなる可能性がある.
そこで,標準的なmIoU指標(すなわち,予測されたマスクとグランドトゥルースのマスクの間のすべてのIoUの平均値)を,アノテータがマスク品質を1(無意味)から10(ピクセルパーフェクト)まで評価するヒト試験で補う.
詳細は付録D.1,E,Gを参照.
デフォルトでは,対話型セグメンテーションにおける標準的な評価プロトコル[92]に従って,グラウンドトゥルースのマスクの「中心」(マスクの内部距離変換の最大値)からポイントをサンプリングする.
SAMは複数のマスクを予測することができるため,デフォルトでモデルの最も自信のあるマスクのみを評価する.
ベースラインはすべてシングルマスクの手法である.
他の強力なベースライン[67, 18]と比較して,我々のベンチマークで最高の性能を示した強力な対話型セグメンテーションであるRITM[92]と主に比較する.

データセット:
多様な画像分布を持つ23のデータセットを新たにコンパイルしたものを使用する.
図8は,データセットの一覧と各データセットからのサンプルを示している(詳細は付録表7を参照).
mIoUの評価には,23のデータセットすべてを使用する.
ヒト試験では,図9bに示すサブセットを使用する(このような研究のリソース要件のため).
このサブセットには,自動メトリクスに従ってSAMがRITMを上回り,下回るデータセットの両方が含まれている.
結果:
まず,mIoUを用いた23のデータセット群に対する自動評価について見てみる.
図9aでデータセットごとの結果をRITMと比較する.
23個のデータセットのうち16個で,SAMが47IoU以下もの差をつけてより高い結果を出している.
また,SAMの3つのマスクのうち,最も信頼できるマスクを選択するのではなく,グランドトゥルースと比較して最も適切なマスクを選択する「オラクル」結果も示している.
これは,自動評価における曖昧性の影響を明らかにするものである.
特に,オラクルで曖昧性解消を行った場合,すべてのデータセットでSAMはRITMを上回る性能を発揮する.
ヒト試験の結果は,図9bに示す.
エラーバーは,平均マスク評価の95%信頼区間である(すべての差は有意であり,詳細については付録Eを参照).
アノテータは一貫して,SAMのマスクの品質を最強のベースラインであるRITMよりも大幅に高く評価していることが観察される.
SAMの出力マスクが1つの「曖昧性非認識」バージョンは,RITMより高いものの,一貫して低い評価である.
SAMの平均評価は7~9の間にあり,これは定性的評価のガイドラインに対応している.
「高得点(7~9ポイント):オブジェクトが識別可能で,エラーが小さく,まれである(例:小さく,大きく不明瞭な切断されたコンポーネントを見逃す...).」
これらの結果は,SAMが有効なマスクを1ポイントから分割することを学習したことを示している.
なお,DRAMやIBDのようなデータセットでは,自動的なメトリクスではSAMの方が悪いが,ヒト試験による調査では常に高い評価を受けている.
図9cは,SimpleClick[67]とFocalClick[18]のベースラインを追加したもので,RITMとSAMよりも低いシングルポイント性能を得ている.
ポイントが1から9に増加するにつれて,手法間のギャップが小さくなっていることがわかる.
これは,タスクが簡単になるにつれて予想されることであり,また,SAMは非常に高いIoU領域に対して最適化されていない.
最後に,図9dでは,デフォルトの中心ポイントサンプリングをランダムポイントサンプリングに置き換えている.
SAMとベースラインとの間のギャップは拡大し,SAMはどちらのサンプリング方法でも同等の結果を得られた.
7.2節:Zero-Shot Edge Detection(Zero-Shotエッジ検出)
アプローチ:
BSDS500[72, 3]を用いて,エッジ検出という古典的な低レベルタスクでSAMを評価した.
マスク自動生成パイプラインの簡略版を使用した.
具体的には,16x16の規則的なフォアグラウンドポイントグリッドでSAMを促し,768個の予測マスク(1ポイントにつき3個)を生成した.
冗長なマスクはNMSによって除去される.
次に,閾値のないマスク確率マップのソーベルフィルタリングと,エッジNMSを含む標準的な軽量後処理を用いてエッジマップを計算する(詳細については付録D.2参照).


結果:
代表的なエッジマップを図10に示す(詳しくは図15を参照).
定性的には,SAMはエッジ検出のための訓練を受けていないにもかかわらず,妥当なエッジマップを生成している.
SAMはグランドトゥルースと比較して,BSDS500でアノテーションされていないエッジを含む,より多くのエッジを予測する.
このバイアスは表3に定量的に反映されている.
50%精度での再現性(R50)は高く,精度は犠牲になっている.
SAMは当然,BSDS500のバイアス,つまりどのエッジを抑制するかを学習する最先端の手法に遅れをとっている.
しかし,SAMは,HED[108](同じくBSDS500で学習)のような先駆的な深層学習手法と比較しても良好であり,時代遅れであることは認めるものの,先行するzero-shot transfer手法よりも大幅に優れている.
7.3節:Zero-Shot Object Proposals(Zero-Shotオブジェクト提案)
アプローチ:
次に,オブジェクト提案の生成という中級タスク[2, 102]についてSAMを評価する.
このタスクはオブジェクト検出の研究において重要な役割を担っており,先駆的なシステム(例:[102, 41, 84])において中間段階として機能している.
オブジェクトプロポーザルを生成するために,我々の自動マスク生成パイプラインを少し修正したものを実行し,マスクをプロポーザルとして出力する(詳細は付録D.3参照).
LVIS v1[44]の標準的なAverage Recall(AR)メトリックを計算する.
LVISに注目したのは,そのカテゴリー数の多さから,困難なテストとなるためである.
我々は,ViTDet[62]検出器(カスケードマスクR-CNN[48, 11] ViT-Hを使用)として実装された強力なベースラインと比較した.
この「ベースライン」は,ARをゲーム化した「Detector Masquerading as Proposal generator」(DMP)法 [16]に相当し,甲乙つけがたいことに注意されたい.

結果:
表4では,ViTDet-Hの検出値をオブジェクト提案として用いる方法(ARを用いたDMP法[16])が,全体として最も優れていることがわかる.
しかし,SAMはいくつかの指標で顕著に優れている.
特に,中型や大型のオブジェクト,希少なオブジェクトや一般的なオブジェクトでは,ViTDet-Hを凌駕する.
実際,SAMはViTDet-Hに対して,小さいオブジェクトや頻度の高いオブジェクトに対してのみ劣勢である.
ViTDet-HはSAMとは異なりLVISで訓練しているため,LVIS特有のアノテーションバイアスを容易に学習することができる.
また,SAMの曖昧性を意識しないバージョン("single out.")とも比較したが,これはすべてのAR指標においてSAMより著しく悪い結果となった.
7.4節:Zero-Shot Instance Segmentation(Zero-Shotインスタンスセグメンテーション)
アプローチ:
より高度なビジョンに移行して,インスタンスセグメンタのセグメンテーションモジュールとしてSAMを使用する.
実装は簡単で,オブジェクト検出器(以前使用したViTDet)を実行し,SAMにその出力ボックスを表示させる.
これは,より大きなシステムでSAMを構成することを示すものである.


結果:
表5では,COCOとLVISにおいて,SAMとViTDetが予測したマスクを比較している.
マスクのAPメトリックを見ると,両データセットでギャップが見られ,SAMはViTDetに遅れをとっているものの,それなりに近づいていることがわかる.
出力を可視化すると,SAMのマスクはViTDetのマスクよりも質的に優れており,境界が鮮明であることが確認された(付録D.4および図16参照).
この観察を調査するために,ViTDetマスクとSAMマスクの品質を1~10の尺度で評価するようアノテータに求める追加のヒト試験を実施した.
図11では,SAMがViTDetを常に上回っていることがわかる.
マスクのAPギャップが大きく,グランドトゥルースの品質が比較的低いCOCOでは(ヒト試験でも実証されている),ViTDetはCOCOマスク特有のバイアスを学習するという仮説がある.
SAMはzero-shot法であるため,これらの(一般的に望ましくない)バイアスを利用することができない.
LVISデータセットは,より質の高いグランドトゥルースを持っているが,まだ特有の特異性(例えば,マスクはホールを含まず,構造上単純な多角形である)やモードマスクとアモーダルマスクのバイアスがある.
ViTDetはこれらのバイアスを利用することができるが,SAMはこれらのバイアスを学習するように訓練されていない.
7.5節:Zero-Shot Text-to-Mask
アプローチ:
最後に,自由形式のテキストからオブジェクトをセグメンテーションするという,さらに高度なタスクについて検討する.
この実験は,SAMがテキストプロンプトを処理できることを示す概念実証である.
これまでの実験では全く同じSAMを使用したが,今回の実験ではSAMの学習手順を変更し,テキストを認識できるようにしたが,新たなテキストアノテーションを必要としないようにした.
具体的には,\(100^2\)以上の面積を持つマスクを手動で収集するごとに,CLIPの画像埋め込みを抽出する.
そして,訓練中に,SAMの最初の対話として,抽出されたCLIP画像埋め込みを促す.
ここで重要なのは,CLIPの画像埋め込みはテキスト埋め込みと整合するように学習されているため,画像埋め込みで学習しても,推論にはテキスト埋め込みを使用できることである.
つまり,推論時にCLIPのテキストエンコーダにテキストを通し,その結果のテキスト埋め込みをSAMへのプロンプトとして与える(詳細は付録D.5参照).

結果:
図12に定性的な結果を示す.
SAMは,"a wheel"のような簡単なテキストプロンプトと"beaver tooth grille"のようなフレーズに基づいてオブジェクトをセグメントすることができる.
SAMがテキストプロンプトのみから正しいオブジェクトを選択できなかった場合,[31]と同様に,追加のポイントによって予測が修正されることがよくある.
7.6節:Ablations(アブレーション)
23のデータセット群に対して,シングル中心ポイントプロンプトプロトコルを用いて,いくつかのアブレーションを実施した.
1つのポイントは曖昧である可能性があり,その曖昧性は,ポイントごとに1つのマスクのみを含むグランドトゥルースでは表現されない可能性があることを思い出してほしい.
SAMはzero-shot transferの設定で動作しているため,SAMのトップランクのマスクとデータアノテーションガイドラインの結果のマスクの間に系統的な偏りがある可能性がある.
そのため,グランドトゥルース(「オラクル」)に対するベストマスクを追加で報告する.

(左)各データエンジンステージは,23のデータセット群に対して改善をもたらし,自動データ(我々のデフォルト)のみを用いた訓練では,3ステージすべてのデータを用いた場合と同様の結果を得ることができた.
(中)SA-1Bの10%以下のデータで訓練したSAMと,SA-1Bの全データで訓練したSAMは同等である.デフォルトでは11M枚の画像で訓練しているが,1M枚の画像を使用するのが実用的な設定である.
(右)SAMの画像エンコーダをスケーリングすると,意味のある,飽和利得が得られる.しかし,設定によっては,より小さな画像エンコーダの方が好ましい場合もある.
図13(左)は,データエンジンステージの累積データで訓練させた場合のSAMの性能をプロットしたものである.
各ステージでmIoUが増加することがわかる.
3つのステージすべてで訓練した場合,自動マスクが手動および半自動マスクを圧倒的に上回る.
この問題を解決するために,訓練中に手動および半自動マスクを10倍オーバーサンプリングすると,最良の結果が得られることがわかった.
この設定は,訓練を複雑にする.
そこで,自動生成されたマスクのみを使用する4番目のセットアップをテストした.
このデータでは,SAMは全データを使用した場合よりもわずかに低い性能(0.5mIoU以下)しか得られなかった.
そこで,デフォルトでは,自動生成されたマスクのみを使用し,訓練の設定を簡略化した.
図13(中)では,データ量の影響について見ている.
SA-1Bには11M枚の画像があり,今回のアブレーションでは1Mと0.1Mに一律にサブサンプリングしている.
0.1M枚の画像では,どの設定でも大きなmIoUの減少が観察された.
しかし,全データセットの約10%である1M枚の画像では,全データセットを使用した場合と同等の結果が得られている.
このデータ領域は,まだ約100Mのマスクが含まれており,多くのユースケースで実用的な設定となる可能性がある.
最後に,図13(右)は,ViT-B,ViT-L,ViT-Hの画像エンコーダを用いた結果である.
ViT-HはViT-Bよりも大幅に改善されたが,ViT-Lに対してはわずかな改善しか見られなかった.
現時点では,画像エンコーダのさらなる拡張は有益ではない.
8章:Discussion(ディスカッション)
基盤モデル:
機械学習の初期から,事前に訓練されたモデルは下流のタスクに適応されてきた[99].
このパラダイムは,近年,規模が重視されるようになり,そのようなモデルは,最近,「基盤モデル」として(再)ブランド化された.
すなわち,「大規模なデータで訓練され,幅広い下流タスクに適応できる」モデルである[8].
我々の仕事は,この定義とよく相関している.
しかし,画像分割のための基盤モデルは,本質的に限られた範囲であることに注意する必要がある.
というのも,コンピュータビジョンの重要なサブセットであり,まだほんの一部だからである.
また,基盤モデルにおける自己教師あり学習の役割を強調する[8]と,我々のアプローチの一面を対比する.
我々のモデルは自己教師あり学習(MAE [47])で初期化されているが,その能力の大部分は大規模な教師あり学習によるものである.
我々のようにデータエンジンが利用可能なアノテーションを拡張できる場合,教師あり学習は効果的な解決策を提供する.
コンポジショナリティ:
訓練済みのモデルは,訓練の時点で想像していた以上の新しい能力を発揮できる.
その顕著な例として,CLIP[82]がDALL-E[83]のような大規模システムのコンポーネントとして使用されていることが挙げられる.
我々の目標は,このような構成をSAMで簡単にできるようにすることである.
そのためには,幅広いセグメンテーションのプロンプトに対して,有効なマスクを予測するようSAMに要求する.
その結果,SAMと他のコンポーネントとの間に信頼性の高いインターフェースを構築することができる.
例えば,MCC[106]は,1枚のRGB-D画像から3D再構成するために,SAMを使用して目的のオブジェクトを容易にセグメント化し,未見のオブジェクトに対する強力な汎化を実現することができる.
別の例では,ウェアラブルデバイスによって検出された視線ポイントを用いてSAMを促すことができ,新しいアプリケーションを可能にする.
SAMは,自己中心的な画像のような新しい領域に汎化する能力があるため,このようなシステムは追加の訓練を必要とせずに動作する.
制限:
SAMは一般的に良好な性能を発揮するが,完璧ではない.
微細な構造を見逃したり,小さな切断されたコンポーネントをハルシネーションしたり,[18]のような「ズームイン」する計算量の多い手法ほど境界が鮮明に表示されないことがある.
一般的に,多くのポイントが提供される場合,専用の対話型セグメンテーション手法がSAMを上回ると予想される(例:[67]).
これらの方法とは異なり,SAMは,高いIoUの対話型セグメンテーションよりも,一般性と幅広い用途のために設計されている.
さらに,SAMはプロンプトをリアルタイムで処理できるが,それにもかかわらず,重い画像エンコーダを使用すると,SAMの全体的な性能はリアルタイムではない.
テキストからマスク(text-to-mask)へのタスクへの挑戦は探索的なものであり,完全に堅牢とは言えないが,もっと努力すれば改善されると信じている.
SAMは多くのタスクを実行できるが,セマンティックおよびパノプティックセグメンテーションを実装した簡単なプロンプトを設計する方法は不明である.
最後に,[7]のようなドメインに特化したツールがあり,それぞれのドメインでSAMを凌駕することが期待できる.
結論:
Segment Anythingプロジェクトは,画像セグメンテーションを基盤モデルの時代へ引き上げる試みである.
我々の主な貢献は,この飛躍を可能にする新しいタスク(プロンプトセグメンテーション),モデル(SAM),およびデータセット(SA-1B)である.
SAMが基盤モデルの地位を獲得するかどうかは,コミュニティでどのように利用されるかによって決まるが,この仕事の視点,1B以上のマスクの公開,そしてプロンプトセグメンテーションモデルが,前途を切り開く助けになることを期待している.
References(参考文献)
※訳注:出版年の後に書いてある数字は,論文が引用されている原文のページ番号を意味します.
- Edward H Adelson. On seeing stuff: the perception of materials by humans and machines. Human vision and electronic imaging VI, 2001. 5
- Bogdan Alexe, Thomas Deselaers, and Vittorio Ferrari. What is an object? CVPR, 2010. 4, 10
- Pablo Arbel´aez, Michael Maire, Charless Fowlkes, and Jitendra Malik. Contour detection and hierarchical image segmentation. TPAMI, 2010. 4, 10, 21, 28
- Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv:1607.06450, 2016. 16
- Hangbo Bao, Li Dong, and Furu Wei. BEiT: BERT pre-training of image transformers. arXiv:2106.08254, 2021. 17
- Dina Bashkirova, Mohamed Abdelfattah, Ziliang Zhu, James Akl, Fadi Alladkani, Ping Hu, Vitaly Ablavsky, Berk Calli, Sarah Adel Bargal, and Kate Saenko. ZeroWaste dataset: Towards deformable object segmentation in cluttered scenes. CVPR, 2022. 9, 20
- Stuart Berg, Dominik Kutra, Thorben Kroeger, Christoph N. Straehle, Bernhard X. Kausler, Carsten Haubold, Martin Schiegg, Janez Ales, Thorsten Beier, Markus Rudy, Kemal Eren, Jaime I. Cervantes, Buote Xu, Fynn Beuttenmueller, Adrian Wolny, Chong Zhang, Ullrich Koethe, Fred A. Hamprecht, and Anna Kreshuk. ilastik: interactive machine learning for (bio)image analysis. Nature Methods, 2019. 12
- Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv:2108.07258, 2021. 1, 12
- Gustav Bredell, Christine Tanner, and Ender Konukoglu. Iterative interaction training for segmentation editing networks. MICCAI, 2018. 17
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. NeurIPS, 2020. 1, 4
- Zhaowei Cai and Nuno Vasconcelos. Cascade R-CNN: Delving into high quality object detection. CVPR, 2018. 10
- Juan C. Caicedo, Allen Goodman, Kyle W. Karhohs, Beth A. Cimini, Jeanelle Ackerman, Marzieh Haghighi, CherKeng Heng, Tim Becker, Minh Doan, Claire McQuin, Mohammad Rohban, Shantanu Singh, and Anne E. Carpenter. Nucleus segmentation across imaging experiments: the 2018 data science bowl. Nature Methods, 2019. 9, 19, 20
- John Canny. A computational approach to edge detection. TPAMI, 1986. 10, 21
- Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with Transformers. ECCV, 2020. 5, 16, 17
- Guillaume Charpiat, Matthias Hofmann, and Bernhard Sch¨olkopf. Automatic image colorization via multimodal predictions. ECCV, 2008. 5, 17
- Neelima Chavali, Harsh Agrawal, Aroma Mahendru, and Dhruv Batra. Object-proposal evaluation protocol is’ gameable’. CVPR, 2016. 10, 21
- Jiazhou Chen, Yanghui Xu, Shufang Lu, Ronghua Liang, and Liangliang Nan. 3D instance segmentation of MVS buildings. IEEE Transactions on Geoscience and Remote Sensing, 2022. 9, 19, 20, 23, 24
- Xi Chen, Zhiyan Zhao, Yilei Zhang, Manni Duan, Donglian Qi, and Hengshuang Zhao. FocalClick: towards practical interactive image segmentation. CVPR, 2022. 8, 9, 12, 19
- Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. CVPR, 2022. 4
- Bowen Cheng, Alex Schwing, and Alexander Kirillov. Perpixel classification is not all you need for semantic segmentation. NeurIPS, 2021. 5, 16, 17
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways. arXiv:2204.02311, 2022. 1
- Luca Ciampi, Carlos Santiago, Joao Costeira, Claudio Gennaro, and Giuseppe Amato. Domain adaptation for traffic density estimation. International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, 2021. 9, 20
- Luca Ciampi, Carlos Santiago, Joao Costeira, Claudio Gennaro, and Giuseppe Amato. Night and day instance segmented park (NDISPark) dataset: a collection of images taken by day and by night for vehicle detection, segmentation and counting in parking areas. Zenodo, 2022. 9, 20
- Nadav Cohen, Yael Newman, and Ariel Shamir. Semantic segmentation in art paintings. Computer Graphics Forum, 2022. 9, 19, 20, 23, 24
- Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes dataset for semantic urban scene understanding. CVPR, 2016. 9, 19, 20
- Bruno da Silva, George Konidaris, and Andrew Barto. Learning parameterized skills. ICML, 2012. 4
- Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling egocentric vision: Collection, pipeline and challenges for EPICKITCHENS- 100. IJCV, 2022. 9, 20, 23, 24
- Ahmad Darkhalil, Dandan Shan, Bin Zhu, Jian Ma, Amlan Kar, Richard Higgins, Sanja Fidler, David Fouhey, and Dima Damen. EPIC-KITCHENS VISOR benchmark: Video segmentations and object relations. NeurIPS, 2022. 9, 19, 20, 23, 24
- Terrance De Vries, Ishan Misra, Changhan Wang, and Laurens Van der Maaten. Does object recognition work for everyone? CVPR workshops, 2019. 18
- Mark D´ıaz, Ian Kivlichan, Rachel Rosen, Dylan Baker, Razvan Amironesei, Vinodkumar Prabhakaran, and Emily Denton. Crowd- WorkSheets: Accounting for individual and collective identities underlying crowdsourced dataset annotation. ACM Conference on Fairness, Accountability, and Transparency, 2022. 25
- Henghui Ding, Scott Cohen, Brian Price, and Xudong Jiang. PhraseClick: toward achieving flexible interactive segmentation by phrase and click. ECCV, 2020. 11
- Piotr Doll´ar and C Lawrence Zitnick. Fast edge detection using structured forests. TPAMI, 2014. 21
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021. 5, 8, 16
- Alireza Fathi, Xiaofeng Ren, and James M. Rehg. Learning to recognize objects in egocentric activities. CVPR, 2011. 9, 19, 20
- Pedro F Felzenszwalb and Daniel P Huttenlocher. Efficient graphbased image segmentation. IJCV, 2004. 10
- Thomas B. Fitzpatrick. The validity and practicality of sun-reactive skin types i through vi. Archives of Dermatology, 1988. 8
- Marco Forte, Brian Price, Scott Cohen, Ning Xu, and Franc¸ois Piti´e. Getting to 99% accuracy in interactive segmentation. arXiv:2003.07932, 2020. 5, 17
- Jean-Michel Fortin, Olivier Gamache, Vincent Grondin, Franc¸ois Pomerleau, and Philippe Gigu`ere. Instance segmentation for autonomous log grasping in forestry operations. IROS, 2022. 9, 20
- Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daum´e Iii, and Kate Crawford. Datasheets for datasets. Communications of the ACM, 2021. 25
- Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin D Cubuk, Quoc V Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation. CVPR, 2021. 16, 18, 22
- Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR, 2014. 10
- Priya Goyal, Piotr Doll´ar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: Training ImageNet in 1 hour. arXiv:1706.02677, 2017. 17
- Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, Vincent Cartillier, Sean Crane, Tien Do, Morrie Doulaty, Akshay Erapalli, Christoph Feichtenhofer, Adriano Fragomeni, Qichen Fu, Christian Fuegen, Abrham Gebreselasie, Cristina Gonzalez, James Hillis, Xuhua Huang, Yifei Huang, Wenqi Jia, Weslie Khoo, Jachym Kolar, Satwik Kottur, Anurag Kumar, Federico Landini, Chao Li, Yanghao Li, Zhenqiang Li, Karttikeya Mangalam, Raghava Modhugu, Jonathan Munro, Tullie Murrell, Takumi Nishiyasu, Will Price, Paola Ruiz Puentes, Merey Ramazanova, Leda Sari, Kiran Somasundaram, Audrey Southerland, Yusuke Sugano, Ruijie Tao, Minh Vo, Yuchen Wang, Xindi Wu, Takuma Yagi, Yunyi Zhu, Pablo Arbelaez, David Crandall, Dima Damen, Giovanni Maria Farinella, Bernard Ghanem, Vamsi Krishna Ithapu, C. V. Jawahar, Hanbyul Joo, Kris Kitani, Haizhou Li, Richard Newcombe, Aude Oliva, Hyun Soo Park, James M. Rehg, Yoichi Sato, Jianbo Shi, Mike Zheng Shou, Antonio Torralba, Lorenzo Torresani, Mingfei Yan, and Jitendra Malik. Ego4D: Around the World in 3,000 Hours of Egocentric Video. CVPR, 2022. 20
- Agrim Gupta, Piotr Dollar, and Ross Girshick. LVIS: A dataset for large vocabulary instance segmentation. CVPR, 2019. 2, 6, 7, 9, 10, 11, 19, 20, 21, 24
- Abner Guzman-Rivera, Dhruv Batra, and Pushmeet Kohli. Multiple choice learning: Learning to produce multiple structured outputs. NeurIPS, 2012. 5, 17
- Timm Haucke, Hjalmar S. K¨uhl, and Volker Steinhage. SOCRATES: Introducing depth in visual wildlife monitoring using stereo vision. Sensors, 2022. 9, 20
- Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. CVPR, 2022. 5, 8, 12, 16, 17
- Kaiming He, Georgia Gkioxari, Piotr Doll´ar, and Ross Girshick. Mask R-CNN. ICCV, 2017. 10
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CVPR, 2016. 16
- Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv:1606.08415, 2016. 16
- Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv:2203.15556, 2022. 1
- Jungseok Hong, Michael Fulton, and Junaed Sattar. TrashCan: A semantically-segmented dataset towards visual detection of marine debris. arXiv:2007.08097, 2020. 9, 19, 20
- Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian QWeinberger. Deep networks with stochastic depth. ECCV, 2016. 17
- Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, and Humphrey Shi. Oneformer: One transformer to rule universal image segmentation. arXiv:2211.06220, 2022. 4
- Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. ICML, 2021. 1
- Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv:2001.08361, 2020. 1
- Michael Kass, Andrew Witkin, and Demetri Terzopoulos. Snakes: Active contour models. IJCV, 1988. 4
- Dahun Kim, Tsung-Yi Lin, Anelia Angelova, In So Kweon, and Weicheng Kuo. Learning open-world object proposals without learning to classify. IEEE Robotics and Automation Letters, 2022. 21
- Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Doll´ar. Panoptic segmentation. CVPR, 2019. 4
- Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, and Vittorio Ferrari. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. IJCV, 2020. 2, 6, 7, 18, 19
- Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. Quantifying the carbon emissions of machine learning. arXiv:1910.09700, 2019. 28
- Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. ECCV, 2022. 5, 10, 11, 16, 21, 23, 24
- Yin Li, Zhefan Ye, and James M. Rehg. Delving into egocentric actions. CVPR, 2015. 9, 20
- Zhuwen Li, Qifeng Chen, and Vladlen Koltun. Interactive image segmentation with latent diversity. CVPR, 2018. 5, 17, 19
- Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. ICCV, 2017. 5, 17
- Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. ECCV, 2014. 2, 4, 6, 7, 11, 18, 19, 20
- Qin Liu, Zhenlin Xu, Gedas Bertasius, and Marc Niethammer. SimpleClick: Interactive image segmentation with simple vision transformers. arXiv:2210.11006, 2022. 8, 9, 12, 19
- Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. ICLR, 2019. 17
- Cathy H Lucas, Daniel OB Jones, Catherine J Hollyhead, Robert H Condon, Carlos M Duarte, William M Graham, Kelly L Robinson, Kylie A Pitt, Mark Schildhauer, and Jim Regetz. Gelatinous zooplankton biomass in the global oceans: geographic variation and environmental drivers. Global Ecology and Biogeography, 2014. 20
- Sabarinath Mahadevan, Paul Voigtlaender, and Bastian Leibe. Iteratively trained interactive segmentation. BMVC, 2018. 4, 17
- Kevis-Kokitsi Maninis, Sergi Caelles, Jordi Pont-Tuset, and Luc Van Gool. Deep extreme cut: From extreme points to object segmentation. CVPR, 2018. 6
- David Martin, Charless Fowlkes, Doron Tal, and Jitendra Malik. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. ICCV, 2001. 10, 21, 28
- Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. 3DV, 2016. 5, 17
- Massimo Minervini, Andreas Fischbach, Hanno Scharr, and Sotirios A. Tsaftaris. Finely-grained annotated datasets for imagebased plant phenotyping. Pattern Recognition Letters, 2016. 9, 20
- Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. Proceedings of the conference on fairness, accountability, and transparency, 2019. 25, 28
- Dim P Papadopoulos, Jasper RR Uijlings, Frank Keller, and Vittorio Ferrari. Extreme clicking for efficient object annotation. ICCV, 2017. 6
- David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. Carbon emissions and large neural network training. arXiv:2104.10350, 2021. 28
- Matthew E Peters,Waleed Ammar, Chandra Bhagavatula, and Russell Power. Semi-supervised sequence tagging with bidirectional language models. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, 2017. 18
- Mengyang Pu, Yaping Huang, Yuming Liu, Qingji Guan, and Haibin Ling. EDTER: Edge detection with transformer. CVPR, 2022. 10
- Mattia Pugliatti and Francesco Topputo. DOORS: Dataset fOr bOuldeRs Segmentation. Zenodo, 2022. 9, 20
- Jiyang Qi, Yan Gao, Yao Hu, Xinggang Wang, Xiaoyu Liu, Xiang Bai, Serge Belongie, Alan Yuille, Philip Torr, and Song Bai. Occluded video instance segmentation: A benchmark. ICCV, 2022. 9, 20, 23, 24
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. ICML, 2021. 1, 2, 4, 5, 8, 12, 16, 22
- Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. ICML, 2021. 1, 4, 12
- Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. NeurIPS, 2015. 6, 10
- Xiaofeng Ren and Jitendra Malik. Learning a classification model for segmentation. ICCV, 2003. 4
- Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. ICCV, 2021. 9, 19, 20
- Candice Schumann, Susanna Ricco, Utsav Prabhu, Vittorio Ferrari, and Caroline Pantofaru. A step toward more inclusive people annotations for fairness. Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, 2021. 8, 19
- Sefik Ilkin Serengil and Alper Ozpinar. LightFace: A hybrid deep face recognition framework. ASYU, 2020. 26
- Sefik Ilkin Serengil and Alper Ozpinar. HyperExtended LightFace: A facial attribute analysis framework. ICEET, 2021. 26
- Jamie Shotton, John Winn, Carsten Rother, and Antonio Criminisi. TextonBoost: Joint appearance, shape and context modeling for mulit-class object recognition and segmentation. ECCV, 2006. 4
- Corey Snyder and Minh Do. STREETS: A novel camera network dataset for traffic flow. NeurIPS, 2019. 9, 20
- Konstantin Sofiiuk, Ilya A Petrov, and Anton Konushin. Reviving iterative training with mask guidance for interactive segmentation. ICIP, 2022. 5, 8, 9, 17, 19, 23, 24, 28
- Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 2014. 16
- Chris Stauffer and W Eric L Grimson. Adaptive background mixture models for real-time tracking. CVPR, 1999. 4
- Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. NeurIPS, 2020. 5, 16
- Yansong Tang, Yi Tian, Jiwen Lu, Jianjiang Feng, and Jie Zhou. Action recognition in RGB-D egocentric videos. ICIP, 2017. 20
- Yansong Tang, ZianWang, Jiwen Lu, Jianjiang Feng, and Jie Zhou. Multi-stream deep neural networks for RGB-D egocentric action recognition. IEEE Transactions on Circuits and Systems for Video Technology, 2019. 20
- The World Bank. The world by income and regions, 2022. https://datatopics.worldbank.org/world-development-indicators/the-world-by-income-and-region.html. 18
- Sebastian Thrun. Is learning the n-th thing any easier than learning the first? NeurIPS, 1995. 12
- Cameron Trotter, Georgia Atkinson, Matt Sharpe, Kirsten Richardson, A. Stephen McGough, Nick Wright, Ben Burville, and Per Berggren. NDD20: A large-scale few-shot dolphin dataset for coarse and fine-grained categorisation. arXiv:2005.13359, 2020. 9, 19, 20, 23, 24
- United States Environmental Protection Agency. Greenhouse Gas Equivalencies Calculator. https://www.epa.gov/energy/greenhouse-gas-equivalencies-calculator, 2022. 28
- Koen EA van de Sande, Jasper RR Uijlings, Theo Gevers, and Arnold WM Smeulders. Segmentation as selective search for object recognition. ICCV, 2011. 10
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. NeurIPS, 2017. 5, 16
- BoyingWang, Libo Zhang, LongyinWen, Xianglong Liu, and Yanjun Wu. Towards real-world prohibited item detection: A largescale x-ray benchmark. CVPR, 2021. 9, 19, 20
- Weiyao Wang, Matt Feiszli, Heng Wang, Jitendra Malik, and Du Tran. Open-world instance segmentation: Exploiting pseudo ground truth from learned pairwise affinity. CVPR, 2022. 21
- Chao-Yuan Wu, Justin Johnson, Jitendra Malik, Christoph Feichtenhofer, and Georgia Gkioxari. Multiview compressive coding for 3D reconstruction. CVPR, 2023. 12
- Jianxiong Xiao, James Hays, Krista Ehinger, Aude Oliva, and Antonio Torralba. SUN database: Large-scale scene recognition from abbey to zoo. CVPR, 2010. 20
- Saining Xie and Zhuowen Tu. Holistically-nested edge detection. ICCV, 2015. 10
- Ning Xu, Brian Price, Scott Cohen, Jimei Yang, and Thomas S Huang. Deep interactive object selection. CVPR, 2016. 4, 19
- Kaiyu Yang, Klint Qinami, Li Fei-Fei, Jia Deng, and Olga Russakovsky. Towards fairer datasets: Filtering and balancing the distribution of the people subtree in the imagenet hierarchy. Proceedings of the 2020 conference on fairness, accountability, and transparency, 2020. 8
- Lei Yang, Yan Zi Wei, Yisheng HE, Wei Sun, Zhenhang Huang, Haibin Huang, and Haoqiang Fan. iShape: A first step towards irregular shape instance segmentation. arXiv:2109.15068, 2021. 9, 20, 23, 24
- Senthil Yogamani, Ciar´an Hughes, Jonathan Horgan, Ganesh Sistu, Padraig Varley, Derek O’Dea, Michal Uric´ar, Stefan Milz, Martin Simon, Karl Amende, et al. WoodScape: A multi-task, multicamera fisheye dataset for autonomous driving. ICCV, 2019. 9, 20
- Lingzhi Zhang, Shenghao Zhou, Simon Stent, and Jianbo Shi. Finegrained egocentric hand-object segmentation: Dataset, model, and applications. ECCV, 2022. 9, 19, 20
- Wenwei Zhang, Jiangmiao Pang, Kai Chen, and Chen Change Loy. K-Net: Towards unified image segmentation. NeurIPS, 2021. 4
- Jieyu Zhao, TianluWang, Mark Yatskar, Vicente Ordonez, and Kai- Wei Chang. Men also like shopping: Reducing gender bias amplification using corpus-level constraints. arXiv:1707.09457, 2017. 8
- Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. TPAMI, 2017. 20
- Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ADE20K dataset. IJCV, 2019. 2, 7, 9, 20
付録A:Segment Anything Model and Task Details(Segment Anything Modelとタスク詳細)
画像エンコーダ:
一般に,画像エンコーダは,CxHxW画像埋め込みを出力する任意のネットワークとすることができる.
スケーラビリティと強力な事前訓練へのアクセスを動機として,我々は,高解像度入力を処理するための最小限の適応を伴うMAE[47]事前訓練済みVision Transformer(ViT)[33] を使用し,特に14x14 windowed attentionと4つの等間隔グローバルアテンションブロックを持つViT-H/16を,[62]に従って使用する.
画像エンコーダの出力は,入力画像の16倍縮小埋め込みである.
我々の実行目標は,各プロンプトをリアルタイムで処理することなので,プロンプトごとではなく画像ごとに1回だけ計算されるため,高い数の画像エンコーダのFLOPsを確保することができる.
標準的な手法(例えば[40])に従い,画像を再スケーリングして短辺をパディングすることで得られる1024x1024の入力解像度を使用する.
したがって,画像埋め込みは64x64になる.
チャンネルの次元を小さくするために,[62]に従って,256チャンネルになるように1x1コンボリューションを使用し,次に同じく256チャンネルで3x3コンボリューションを使用する.
それぞれの畳み込みは,レイヤ正規化[4]に続いて行われる.
プロンプトエンコーダ:
疎なプロンプトは,以下のように256次元のベクトル埋め込みにマッピングされる.
ポイントは,ポイントの位置の位置エンコーディング[95]と,そのポイントがフォアグラウンドかバックグラウンドかを示す2つの学習済みエンコーディングのうちの1つの合計として表現される.
ボックスは,(1)左上の角の位置エンコーディングと,「左上の角」を表す学習済みエンコーディングの和,(2)同じ構造で「右下の角」を表す学習済みエンコーディングの2つのエンコーディングで表現される.
最後に,自由形式のテキストを表現するために,CLIP[82]のテキストエンコーダを用いる(一般的にはどのようなテキストエンコーダでも可能である).
本章では幾何学的プロンプトに焦点を当て,テキストプロンプトについては付録D.5で詳しく説明する.
密度の高いプロンプト(すなわちマスク)は,画像と空間的な対応関係がある.
入力画像より4倍低い解像度でマスクを入力し,出力チャンネル4と16をそれぞれ2x2,stride-2コンボリューションを使ってさらに4倍ダウンスケールする.
最後の1x1畳み込みは,チャンネル次元を256にマッピングする.
各層はGELU活性化関数[50]と層の正規化によって分離される.
その後,マスクと画像埋め込みが要素ごとに追加される.
マスクプロンプトがない場合は,「マスクなし」を表す学習済み埋め込みが,各画像埋め込み位置に追加される.
軽量マスクデコーダ:
このモジュールは,画像埋め込みとプロンプト埋め込みのセットを,出力マスクに効率的にマッピングする.
これらの入力を組み合わせるために,我々はTransformerセグメンテーションモデル[14, 20]からヒントを得て,標準的なTransformerデコーダ[103]を修正する.
このデコーダを適用する前に,まずプロンプト埋め込みのセットに,デコーダの出力で使用される学習済みの出力トークン埋め込みを挿入する([33]の[class]トークンに類似している).
簡単のため,これらの埋め込み(画像埋め込みを除く)を総称して「トークン」と呼ぶことにする.

デコーダの設計を図14に示す.
各デコーダ層は4つのステップを実行する.
- トークンに対するセルフアテンション
- トークンから画像埋め込みへのクロスアテンション
- ポイント毎のMLPによる各トークンの更新
- 画像埋め込みからトークンへのクロスアテンション(クエリとして)
この最後のステップでは,画像埋め込みをプロンプト情報で更新する.
クロスアテンション中,画像埋め込みは\(64^2\)個の256次元ベクトルの集合として扱われる.
各自/クロスアテンション・MLPは,訓練時に残差接続[49],レイヤ正規化,ドロップアウト[93]を0.1としている.
次のデコーダ層は,更新されたトークンと,前の層から更新された画像埋め込みを受け取る.
ここでは2層のデコーダを使用する.
デコーダが重要な幾何学的情報にアクセスできるようにするため,位置エンコーディングは,アテンション層に参加するたびに画像埋め込みに追加される.
さらに,元のプロンプトトークン全体(位置エンコーディングを含む)が,アテンション層に参加するたびに,更新されたトークンに再追加される.
これにより,プロンプトトークンの幾何学的位置とタイプの両方に強く依存することができる.
デコーダを実行した後,2つの転置畳み込み層で,更新された画像埋め込みを4倍アップサンプリングする(現在,入力画像に対して4倍ダウンスケールされている).
そして,トークンはもう一度画像埋め込みに参加し,更新された出力トークン埋め込みを小さな3層MLPに渡して,アップスケールされた画像埋め込みのチャンネル次元に一致するベクトルを出力させる.
最後に,アップスケールされた画像埋め込みとMLPの出力の間の空間的な点和積でマスクを予測する.
Transformerは256の埋め込み次元を使用する.
TransformerのMLPブロックは2048という大きな内部次元を持つが,MLPは比較的数が少ない(20を超えることはほとんどない)プロンプトトークンのみに適用される.
しかし,64x64の画像を埋め込むクロスアテンション層では,計算効率のために,クエリ,キー,バリューのチャンネル次元を2分の1に減らして128にしている.
すべてのアテンション層で8個のヘッドを使用する.
出力画像の埋め込みを拡大するために使用される転置畳み込みは,2x2,stride 2,出力チャンネルの次元は64と32で,GELU活性化関数を持つ.
これらはレイヤの正規化によって分離されている.
モデルの曖昧性を認識させる:
このように,1つの入力プロンプトが複数の有効なマスクに対応するという意味で曖昧な場合があり,モデルはこれらのマスクの平均を学習することになる.
この問題を簡単な修正で解消する.
単一のマスクを予測する代わりに,少数の出力トークンを使って複数のマスクを同時に予測するのである.
デフォルトでは3つのマスクを予測する.
これは,ネストしたマスクを表現するには,3つのレイヤ(全体,部分,サブパーツ)で十分であることが多いためである.
訓練中,グランドトゥルースと予測された各マスクの間の損失(後述)を計算するが,最も低い損失からバックプロパゲートするだけである.
これは,複数の出力を持つモデルでよく使われる手法である[15, 45, 64].
アプリケーションで使用するために,我々は予測されたマスクをランク付けしたいので,各予測されたマスクとそれがカバーするオブジェクトの間のIoUを推定する小さなヘッド(追加の出力トークンで動作)を追加する.
曖昧性は複数のプロンプトでより希薄になり,3つの出力マスクは通常類似したものになる.
訓練時の縮退損失の計算を最小化し,単一の曖昧でないマスクが規則的な勾配信号を受け取るようにするため,複数のプロンプトが与えられたときに単一のマスクのみを予測する.
これは,追加のマスク予測のために4番目の出力トークンを追加することによって達成される.
この4番目のマスクは,単一のプロンプトでは決して返されず,複数のプロンプトで返される唯一のマスクである.
損失:
我々は,[20, 14]に従い,焦点損失[65]とダイス損失[73]の線形結合で,焦点損失とダイス損失の比率を20:1としてマスク予測を監督する.
[20, 14]とは異なり,各デコーダ層の後の補助的な深い監視は役に立たないことが観察される.
IoU予測ヘッドは,IoU予測とグランドトゥルースマスクとの予測されたマスクのIoUとの間の平均二乗誤差損失で訓練される.
これは,1.0という一定のスケーリングファクターでマスクの損失に加えられる.
訓練アルゴリズム:
最近のアプローチ[92, 37]に従い,訓練中に対話型セグメンテーションの設定をシミュレートする.
まず,フォアグラウンドポイントまたは境界ボックスのいずれかが,等確率で,ターゲットマスクにランダムに選択される.
ポイントは,グランドトゥルースマスクから一様にサンプリングされる.
ボックスはグランドトゥルースマスクのバウンディングボックスとし,各座標にボックスのサイドレングスの10%に等しい標準偏差を持つランダムノイズを最大20ピクセルまで付加する.
このノイズプロファイルは,インスタンスセグメンテーションのようにターゲットオブジェクトの周りにタイトなボックスを生成するアプリケーションと,ユーザがルーズなボックスを描くことができるインタラクティブセグメンテーションの間の妥当な妥協点である.
この最初のプロンプトから予測を行った後,後続のポイントは,前のマスク予測とグランドトゥルースのマスクとの間の誤差領域から一様に選択される.
誤差領域が偽陰性または偽陽性の場合,各々の新しいポイントはそれぞれフォアグラウンドまたはバックグラウンドとなる.
また,モデルへの追加プロンプトとして,前の反復のマスク予測も供給する.
次の反復に最大限の情報を提供するため,2値化されたマスクの代わりに,閾値のないマスクのロジットを提供する.
複数のマスクが返された場合,次の反復に渡され,次のポイントのサンプリングに使用されるマスクは,予測されたIoUが最も高いものである.
8つのポイントを繰り返しサンプリングすると,収穫が少なくなることがわかる(最大16個までテスト済み).
さらに,モデルにマスクの恩恵を受けさせるために,追加のポイントをサンプリングしない反復を2回行う.
これらの繰り返しのうち1つは,8つの繰り返しサンプリングされたポイントの間にランダムに挿入され,もう1つは常に最後に挿入される.
つまり,1つの初期入力プロンプトのサンプリング,8つの反復サンプリングポイント,そして,モデル自身のマスク予測を改良するために学習できるように,新しい外部情報がモデルに供給されない2つの反復の合計11回の反復を行う.
比較的多くの反復回数を使用することが可能なのは,我々の軽量マスクデコーダが画像エンコーダの計算量の1%未満しか必要とせず,したがって,各反復が小さなオーバヘッドしか追加しないためであることに注意されたい.
これは,オプティマイザの更新ごとに1つまたは数個の対話的なステップしか実行しない以前の対話的手法とは異なる[70, 9, 37, 92].
訓練レシピ:
AdamW[68]オプティマイザ(\(\beta_1 = 0.9\), \(\beta_2 = 0.999\))と線形学習率ウォームアップ[42]で250反復,ステップ毎の学習率減衰スケジュールで使用する.
ウォームアップ後の初期学習率(lr)は\(8e^{-4}\)である.
(2SA-1Bエポック以下で)90k反復訓練し,60k反復でlrを10倍,86,666反復で再び10倍減少させる.
バッチサイズは256画像である.
SAMを正則化するために,Weight Decay(荷重減衰)(wd)を0.1に設定し,ドロップパス[53](dp)を0.4の割合で適用する.
レイヤ毎の学習率減衰 [5](ld)を0.8とする.
データ拡張は適用しない.
SAMはMAE[47]で事前訓練されたViT-Hから初期化する.
大きな画像エンコーダと1024x1024の入力サイズのため,256のGPUに学習を分散させる.
GPUのメモリ使用量を制限するため,GPUごとに最大64個のランダムサンプリングマスクで訓練を行う.
さらに,SA-1Bマスクを軽くフィルタリングして,画像の90%以上をカバーするマスクを破棄すると,結果が定性的に改善されることがわかった.
アブレーションやその他の訓練のバリエーション(例えば,付録D.5のtext-to-mask)については,以下のように上記のデフォルトレシピから逸脱している.
第1および第2データエンジンステージからのデータのみで訓練する場合,[0.1, 2.0]のスケール範囲を持つ大規模ジッタ[40]で入力を拡張する.
直感的には,訓練データがより限られている場合,データの拡張は有用であると思われる.
ViT-BとViT-Lを訓練するために,128GPUに分散されたバッチサイズ128で180k反復を使用する.
我々はViT-B/Lに対して,それぞれ \(lr = 8e^{-4}/4e^{-4}\),\(ld = 0.6/0.8\),\(wd = 0.1\),\(dp = 0.6/0.4\)を設定する.
付録B:Automatic Mask Generation Details(自動マスク生成の詳細)
ここでは,公開されたSA-1Bの生成に使用されたデータエンジンの全自動ステージの詳細について説明する.
クロッピング:
マスクは,フル画像上の32x32ポイントの規則的なグリッドと,16x16および8x8の規則的なポイントグリッドを用いてそれぞれ2x2および4x4の部分的に重なったウィンドウから生じる20の追加ズームイン画像クロップから生成した.
トリミングには元の高解像度画像を使用した(使用したのはこの時だけ).
クロップの内側の境界線に触れるマスクは削除した.
標準的な貪欲なボックスベースのNMS(ボックスは効率化のために使用)を,2段階(最初は各クロップ内,2回目はクロップ間)で適用した.
作物内でNMSを適用する場合,モデルの予測したIoUを使用してマスクのランク付けを行った.
クロップ間でNMSを適用する場合,ソースクロップに基づき,最も拡大されたもの(すなわち4x4クロップのもの)から最も縮小されたもの(すなわちオリジナル画像)へとマスクをランク付けした.
いずれの場合も,NMSの閾値は0.7を使用した.
フィルタリング:
マスクの品質を高めるために,3つのフィルタを使用した.
まず,自信のあるマスクだけを残すために,モデルの予測したIoUスコアを88.0の閾値でフィルタリングした.
次に,安定したマスクだけを残すために,同じソフトマスクから得られた2つのバイナリマスクを,異なる値で閾値処理することで比較した.
その結果,-1閾値と+1閾値のマスクのペア間のIoUが95.0以上である場合にのみ,予測値(すなわち,ロジットを0に閾値処理した結果のバイナリマスク)を保持した.
第3に,時折,自動マスクが画像全体を覆うことがあることに気づいた.
これらのマスクは一般的に面白くないので,画像の95%以上をカバーするマスクを除去することでフィルタリングを行った.
すべてのフィルタリングの閾値は,5章で説明した方法を用いてプロのアノテータが判断したように,多数のマスクと高いマスク品質の両方を達成するように選択された.
後処理:
後処理で簡単に軽減できる2つのエラータイプが観察された.
まず,マスクの4%に小さな偽成分が含まれていると推定される.
このため,面積が100ピクセル以下の連結成分を除去した(最大成分がこの閾値以下の場合はマスク全体の除去も含む).
次に,4%のマスクには小さなホールが含まれていると推定される.
このため,面積が100ピクセル未満のホールを埋めた.
ホールは,反転したマスクの構成要素として識別された.
自動マスク生成モデル:
我々は,完全自動マスク生成のための特別なバージョンのSAMを訓練し,マスク生成の特性を向上させるために推論速度を犠牲にした.
ここでは,デフォルトのSAMとデータ生成に使用したSAMの違いを記す.
大規模なジッタデータ拡張[40]を用いて,より長い時間(90kではなく177656回)訓練し,シミュレーション対話型訓練ではポイントとマスクのプロンプトのみ(ボックスなし),訓練中にマスクあたり4ポイントのみをサンプリングした(デフォルトの9ポイントから4ポイントに減らすと訓練反復が速くなり1ポイント性能に影響はないが,より多くのポイントで評価すると,mIoUには影響がある).
最後にマスクデコーダは2層ではなく3層を使用した.
SA-1Bの例.図2にSA-1Bのサンプルを示す.
その他の例については,データセットエクスプローラを参照されたい.
付録C:RAI Additional Details(RAI追加情報)
SA-1Bの地理情報を推論する.
SA-1Bの画像にはジオタグが付けられていないが,各画像にはその内容と撮影場所を説明するキャプションが付けられている.
これらのキャプションから,Elmoベースの名前付きエンティティ認識モデル[78]を用いて,おおよその画像の地理的位置を推論する.
抽出された各ロケーションエンティティは,一致するすべての国,州,都市にマッピングされる.
キャプションは,まず一致する国,次に州,最後に都市を考慮することで,1つの国にマッピングされる.
この方法には,曖昧性とバイアスの可能性があることに注意されたい(例えば,「ジョージア」は国を指す場合と米国の州を指す場合がある).
そのため,抽出された位置はデータセット全体の分析に使用するが,推定された位置は公開しない.
また,画像提供者の要求により,キャプションの公開も行わない.
COCOとOpen Imagesの地理情報を推論する.
COCO[66]とOpen Images[60]のデータセットはジオロケーションを提供しない.
[29]に従い,Flickr APIを使用して地理的なメタデータを取得する.
COCOの訓練セット(19,562枚)の24%,Open Imagesの訓練セット(493,517枚,マスク付き画像のみ考慮)の18%の位置を取得した.
地理情報は近似値であり,この情報を持つ画像のサンプルは,データセット全体の分布と完全に一致しない可能性があることに注意されたい.
所得情報の推論:
各画像から推測される国を,The World Bank [98]が定義するレベルを用いて所得レベルを調べる.
アッパーミドルレベルとローワーミドルレベルを1つのミドルレベルに統合する.
セグメント化する人々の公平性:
SAMの人物のセグメンテーションにおける公平性を調査するために,Open Images[60]のMore Inclusive Annotations for People(MIAP)[87]テストセットのアノテーションを使用し,性別の認識と年齢層の認識でSAMの性能を比較することができる.
MIAPはボックスアノテーションを提供するが,この分析にはグランドトゥルースマスクが必要である.
グランドトゥルースマスクを得るために,対応するバウンディングボックスがMIAPのアノテーション付きバウンディングボックスと1%のマージン(相対的なボックスの辺の長さに基づく)内にある場合,Open Imagesから各人物カテゴリマスクを選択し,3.9kマスクが得られた.

衣類のセグメントの公平性:
我々は6章からの分析を衣服のセグメンテーションに拡張する.
服を着ている人の属性に対するSAMの性能を見てみる.
我々は,服のスーパークラスの下にカテゴリーを持ち,MIAPの人物ボックス内に存在するOpen Imagesのすべての6.5kのグランドトゥルースマスクを使用する.
表6では,認識された性別の表示と年齢層で性能を比較している.
SAMは,95%信頼区間がバラバラで,主に男性的な服装の人のセグメンテーションに優れていることがわかる.
この差は,1ポイント評価から3ポイント評価に移行する際に縮まる.
年齢層による差は有意ではない.
この結果は,1ポイントのプロンプトで性別を認識した上で服をセグメンテーションする際に偏りがあることを示しており,SAMのユーザにはこの限界に留意してもらうことを推奨する.
付録D:Experiment Implementation Details(実験の実装の詳細)
付録D.1:Zero-Shot Single Point Valid Mask Evaluation(Zero-Shotシングルポイント有効マスク評価)

データセット:
先行研究による23種類の多様なセグメンテーションデータセットを用いて,本モデルのzero-shot transfer能力を評価するために,新しいセグメンテーションベンチマークを構築した.
各データセットの説明は,表7に示す.
例としては,本文の図8を参照.
このデータセットは,自己中心的画像[34, 28, 113],顕微鏡画像[12],X線画像[104],水中画像[52, 100],空中画像[17],シミュレーション画像[86],運転画像[25],そして絵画[24] など,様々な領域をカバーしている.
効率的な評価のために,15k以上のマスクを持つデータセットをサブサンプリングした.
具体的には,サンプリングされた画像のマスクの総数が10k以下になるように,画像をランダムに選択した.
また,すべてのデータセットにおいて,人物の顔にぼかしをかけた.
ポイントサンプリング:
デフォルトのポイントサンプリングは,対話型セグメンテーションの標準的な手法[109, 64, 92]に従っている.
最初のポイントは,オブジェクトの境界から最も遠いポイントとして決定論的に選択される.
後続の各ポイントは,グランドトゥルースと前の予測との間のエラー領域の境界から最も遠いポイントである.
いくつかの実験(指定された場合)では,最初のポイントが決定論的に選択された「中心」ポイントではなく,ランダムなポイントである,より困難なサンプリング戦略を使用している.
後続の各ポイントは,上記のように選択される.
この設定は,視線からのプロンプトのように,最初のポイントがマスクの中心付近に確実に存在しない使用例をよりよく反映している.
評価:
Nポイントプロンプト後の予測値と地上絵のマスクとの間のIoUを測定する.
ここで,N = {1, 2, 3, 5, 9}であり,ポイントは上記のいずれかの戦略で反復的にサンプリングされる.
データセットごとのmIoUは,データセット内のすべてのオブジェクトで平均化されたマスクごとのIoUである.
最後に,全23データセットのデータセット毎のmIoUを平均化したトップラインメトリックを報告する.
我々の評価は,X%のIoUを達成するために必要な平均ポイント数を最大20ポイントで測定する,標準的な対話型セグメンテーション評価プロトコルとは異なるものである.
我々のユースケースの多くは,プロンプトが1つだけ,あるいはごくわずかであるため,わずかポイント,あるいは数ポイント後の予測に焦点を当てる.
リアルタイムでプロンプトを処理する必要がある我々のアプリケーションに焦点を当てると,多数のポイントを使用する場合,最高の対話型セグメンテーションモデルがSAMを上回ることが期待される.
ベースライン:
最近の3つの強力な対話型ベースライン(RITM[92],FocalClick[18],SimpleClick[67])を使用する.
それぞれについて,著者によって公開されている最も広範なデータセットで訓練された最大のモデルを使用する.
RITMでは,著者らが紹介したCOCO[66]とLVIS[44]の組み合わせで学習したHRNet32 IT-Mを使用する.
FocalClickでは,8種類のセグメンテーションデータセットを含む「複合データセット」[18]で学習させたSegFormerB3-S2を使用する.
SimpleClickでは,COCOとLVISの組み合わせで学習させたViT-H448を使用する.
データの前処理(データの拡張や画像のリサイズなど)については,提案されたデフォルトの戦略に従い,評価のためのパラメータの変更や適応は行わない.
実験の結果,RITMは23のデータセットにおいて,1ポイントの評価で他のベースラインよりも優れていることが確認された.
したがって,RITMをデフォルトのベースラインとして使用する.
より多くのポイントで評価する場合は,すべてのベースラインの結果を報告する.
シングルポイントの曖昧性とオラクル評価:
Nポイントプロンプト後のIoUに加え,SAMの3つの予測のうち,最もグランドトゥルースに一致する予測マスクを評価することにより,1ポイントでのSAMの「オラクル」性能を報告する(デフォルトのようにSAM自身が1位になったものを使うのではなく,SAMの予測マスクが1位になる).
このプロトコルは,複数の有効なオブジェクトの中から1つの正しいマスクを推測する要件を緩和することで,1ポイントのプロンプトの曖昧性に対処する.
付録D.2:Zero-Shot Edge Detection(Zero-Shotエッジ検出)
データセットとメトリクス:
BSDS500[72, 3]を用いてzero-shotエッジ検出の実験を行った.
各画像のグランドトゥルースは,5人の異なる被験者の手動アノテーションから得られたものである.
エッジ検出のための4つの標準的なメトリクス[3, 32]:最適データセットスケール(ODS:Optimal Dataset Scale),最適画像スケール(OIS:Optimal Image Scale),平均精度(AP:Average Precision),50%精度での再現性(R50:Recall at 50% Precision)を用いて200画像のテストサブセットについて結果を報告する.
メソッド:
zero-shot transfer転送では,自動マスク生成パイプラインの簡略版を使用する.
16x16の規則的なフォアグラウンドポイントグリッドでSAMを促し,768個の予測マスク(ポイント毎に3個)を得た.
予測されるIoUや安定性によるフィルタリングは行わない.
冗長なマスクはNMSによって除去される.
次に,残りのマスクの閾値のない確率マップにソーベルフィルタを適用し,マスクの外側の境界ピクセルと交差しない場合は値をゼロに設定する.
最後に,すべての予測値に対してピクセル単位の最大値をとり,その結果を[0, 1]に線形正規化し,エッジNMS[13]を適用してエッジを薄くする.

ビジュアライゼーション:
図15では,SAMによるzero-shotエッジ予測の追加例を示している.
これらの定性的な例は,エッジ検出のための訓練を受けていないにもかかわらず,SAMがいかに賢明なエッジマップを出力する傾向があるかをさらに説明するものである.
エッジは人間のアノテーションとよく一致することがわかる.
しかし,前述のように,SAMはエッジ検出のための訓練を受けていないため,BSDS500データセットのバイアスを学習せず,グランドトゥルースのアノテーションに存在するよりも多くのエッジを出力することがある.
付録D.3:Zero-Shot Object Proposals(Zero-Shotオブジェクト提案)
データセットとメトリクス:
LVIS v1検証セット[44]の1000プロポーザルでマスクの標準的な平均リコール(AR)メトリックを報告する.
LVISは1203のオブジェクトクラスに対して高品質なマスクを持っているので,オブジェクト提案生成のための困難なテストを提供する.
我々は,LVISの1203クラス以外の多くの有効なマスクを生成する可能性が高い,我々のモデルのオープンワールドの性質のために,AR@1000に焦点を当てる.
頻度の高いカテゴリー,一般的なカテゴリー,希少なカテゴリーの性能を測定するために,AR@1000を使用するが,対応するLVISカテゴリーだけを含むグランドトゥルースセットに対して測定する.
ベースライン:
我々は,LVIS上のAPによる[62]から最も強いモデルであるカスケードViTDet-Hをベースラインとして使用する.
本文で述べたように,ドメイン内で訓練されたオブジェクト検出器はARを「ゲーム」することができ[16],オープンワールドの提案やセグメンテーションに焦点を当てた他のモデルよりも強いベースラインになることが期待される[58, 105].
1000の提案を生成するために,3つのカスケードステージのスコア閾値を無効にし,ステージごとの予測数の最大値を1000に上げるようにした.
メソッド:
zero-shot transferには,SAMの自動マスク生成パイプラインの修正版を使用する.
まず,推論時間をViTDetと同等にするために,画像の切り抜き処理を行わない.
次に,予測されるIoUと安定性によるフィルタリングを除去する.
これにより,1画像あたり1000枚以下のマスクを得るために,入力ポイントグリッドとNMS閾値の重複マスク抑制という2つの調整可能なパラメータが残った.
64x64のポイントグリッドとNMSの閾値0.9を選択し,平均して画像あたり900枚以下のマスクを生成することにした.
評価時には,1つの画像に1000以上のマスクが提案されている場合,信頼度と安定度の平均値でランク付けされ,上位1000の提案に切り捨てられる.
この課題では,1つの入力ポイントから複数のスケールで生成された提案が想起に役立つはずなので,SAMの複数のマスクを出力する機能が特に有用であるという仮説が成り立つ.
これを検証するために,3つのマスクの代わりに1つのマスクしか出力しないSAM(SAM - single-output)と比較した.
このモデルでは生成されるマスクの数が少ないため,サンプリングされるポイントの数を128x128,NMSの閾値を0.95とさらに増やし,平均して画像あたり950枚以下のマスクが得られるようにした.
さらに,単一出力のSAMは,自動マスク生成パイプラインでNMSのためのマスクのランク付けに使用されるIoUスコアを生成しないため,代わりにマスクがランダムにランク付けされる.
これは,マスクの最大ロジット値をモデルの信頼性の代用とするような,より洗練されたマスクのランク付け方法と同様の性能を持つことがテストから示唆されている.
付録D.4:Zero-Shot Instance Segmentation(Zero-Shotインスタンスセグメンテーション)
メソッド:
zero-shotインスタンス分割のために,COCOとLVIS v1検証分割の完全教師ありViTDet-Hによって出力されたボックスでSAMをプロンプトする.
さらに,最も信頼性の高い予測マスクとボックスプロンプトをマスクデコーダに送り,最終的な予測を行うことで,マスクリファインメントの反復を適用する.
図16に,LVISで予測されたzero-shotインスタンスセグメンテーションを示す.
SAMはViTDetと比較して,よりきれいな境界を持つ高品質のマスクを生成する傾向がある.
この観察結果は,7.4節でヒト試験により確認した.
zero-shotモデルであるSAMは,データセットのアノテーションバイアスを学習することができないことに注意されたい.
例えば,SAMはプレートに対して有効なモード予測を行うが,LVISマスクは設計上ホールを含むことができないため,プレートは非モード的にアノテーションされることがわかる.
付録D.5:Zero-Shot Text-to-Mask
モデルと訓練:
テキストと画像の埋め込みを計算するために,公開されている最大のCLIPモデル[82](ViT-L/14@336px)を使用し,使用前に\(l^2\)正規化する.
SAMの訓練には,データエンジンの最初の2つのステージのマスクを使用する.
さらに,\(100^2\)ピクセルより小さい面積のマスクはすべて廃棄する.
このモデルは,大規模ジッタ[40]を用いて,バッチサイズ128で120k回反復して訓練する.
その他の訓練パラメータはすべてデフォルト設定に従った.
訓練プロンプトを生成:
入力プロンプトを抽出するために,まず各マスクの境界ボックスを1倍から2倍のランダムな倍率で拡大し,拡大したボックスを縦横比を保つように正方形に切り出し,336x336ピクセルにリサイズする.
このクロップをCLIP画像エンコーダに送る前に,50%の確率でマスクの外側のピクセルをゼロにする.
また,埋め込みが対象物に集中するように,最後のレイヤでマスクされたアテンションを使い,出力トークンからマスク内の画像位置への注意を制限している.
最後に,我々のプロンプトは出力トークンの埋め込みになる.
訓練では,まずCLIPベースのプロンプトを提供し,その後,予測を洗練させるために追加の反復ポイントプロンプトを提供する.
推論:
推論時にはCLIPのテキストエンコーダをそのまま利用し,SAMのプロンプトを作成する.
CLIPでは,テキストと画像の埋め込みが整列されているため,推論時にテキストベースのプロンプトを使用しながら,明示的なテキスト監視なしで訓練できることを利用している.
付録D.6:Probing the Latent Space of SAM(SAMの潜伏空間を探る)
最後に,SAMが学習する潜在空間を定性的に探るための初期調査を実施する.
特に,SAMが明示的な意味監視の下で訓練されていないにもかかわらず,その表現に何らかの意味性を取り込むことができるかどうかに関心がある.
そこで,マスクの周囲を切り取った画像とその水平反転画像からSAMの画像埋め込みを抽出し,画像埋め込みに2値マスクを乗じ,空間位置の平均をとることでマスク埋め込みを計算した.
図17に,同一画像内のクエリマスクと類似マスク(潜在空間内)の3例を示す.
各クエリの最近傍は,不完全ではあるが,形状と意味の類似性を示すことが観察される.
これらの結果は予備的なものであるが,SAMによる表現が,さらなるデータのラベリング,データセットの内容の理解,あるいは下流タスクの特徴としてなど,様々な目的で有用であることを示している.
付録E:Human Study Experimental Design(ヒト試験の実験デザイン)
ここでは,7.1節および7.4節でマスク品質の評価に用いたヒト試験の詳細を説明する.
ヒト試験の目的は,予測されるマスク品質の尺度として,グランドトゥルースに対するIoUを用いることの2つの限界に対処することである.
最初の限界は,1ポイントのような曖昧な入力に対して,グランドトゥルースとは異なるオブジェクトの有効なマスクを返すと,モデルが強くペナルティを受ける可能性があることである.
第2の制限は,グランドトゥルースのマスクは,エッジの品質における系統的なエラーや,オクルージョン(オブジェクトが奥にあるオブジェクトを隠している状態)のオブジェクトをモードまたはアモーダルにセグメント化する決定など,様々なバイアスを含む場合があることである.
ドメイン内で訓練されたモデルは,これらのバイアスを学習し,必ずしも優れたマスクを生成することなく,より高いIoUを得ることができる.
このような問題を軽減するために,人間のレビューによって,基礎となるグランドトゥルースマスクに依存しないマスク品質の尺度を得ることができる.
モデル:
シングルポイント評価では,RITM[92],シングル出力のSAM,およびSAMを使用して,2つの仮説を検証した.
第1に,SAMは,シングルポイントを与えられたとき,グランドトゥルースとのIoUなどのメトリクスが明らかにしない場合でも,ベースラインの対話型セグメンテーションモデルよりも視覚的に高品質のマスクを生成するという仮説である.
第2に,SAMのマスクの曖昧性を解消する能力は,シングルポイント入力のマスク品質を向上させるという仮説である.
なぜなら,シングルポイント出力のSAMは,曖昧なマスクの平均値をマスクとして返すことがあるからである.
セグメンテーションの実験では,カスケードViTDet-H[62]とSAMを評価し,SAMは検証データセットの特定のアノテーションバイアスを学習できないためAPが低くても,視覚的に高品質のマスクが生成されるという仮説を検証している.
データセット:
シングルポイント実験では,23のデータセットから7つのデータセットを選択する.
これは,全データセットを人間がレビューするには大きすぎるためである.
LVIS v0.5[17],VISOR[28, 27],DRAM[24],IBD[17],NDD20[100],OVIS[81],iShape[111]を選び,シーンレベル,エゴセントリック,描画,頭上,水中,合成画像など,多様な画像のコレクションを提供している.
さらに,このセットには,SAMがIoUメトリクスでRITMを上回ったデータセットと,その逆のデータセットの両方が含まれている.
インスタンスのセグメンテーション実験では,LVIS v1検証セットを使用し,LVISで訓練されたViTDetと直接比較できるようにした.
メソドロジー:
モデルによって生成されたマスクをプロのアノテータに提示し,提供されたガイドライン(ガイドラインの全文は付録Gを参照)を用いて各マスクを評価するよう依頼した.
アノテータは,データエンジンのために手動でアノテーションされたマスクを収集したのと同じ会社から調達したものである.
アノテータは,画像,1つのモデルの予測マスク,モデルへの入力(1つのポイントまたは1つのボックス)にアクセスし,3つの基準でマスクを判断するよう求められた.
- マスクは有効なオブジェクトに対応しているか?
- マスクはきれいな境界を持っているか?
- マスクは入力に対応しているか?
そして,マスクの全体的な品質を示す1~10の評価を提出した.
スコア1は,全く対象物に対応しないマスクであることを示す.
低スコア(2~4)は,他のオブジェクトの巨大な領域を含む,または無意味な境界の大きな領域を持つなど,マスクに大きな誤りがあることを示す.
中スコア(5~6)は,ほとんど認識できるが,意味や境界線に大きな誤りがあるマスクを示す.
高スコア(7~9)は,わずかな境界の誤りしかないマスクである.
そしてスコア10は,目に見えるエラーがないマスクのスコアである.
アノテータには5種類のビューが用意され,それぞれ異なるエラータイプの識別に役立つように設計されている.
シングルポイントの実験では,zero-shot対話型セグメンテーションのベンチマークに使用したのと同じサブセットから,データセットごとに1000枚のマスクをランダムに選択した(これらのサブセットの詳細については付録D.1参照).
モデル入力は,マスクのエッジからの距離変換の最大値として計算された最も中心なポイントであった.
インスタンスセグメンテーション実験では,LVIS v1検証セットから1000枚のマスクを選択し,モデル入力はLVIS ground truth boxとした.
すべての実験において,\(24^2\)ピクセルより小さいサイズのマスクは,評価者に小さすぎて正確に判断できないマスクを見せないために,サンプリングから除外した.
また,メモリとディスプレイの都合上,大きな画像は最大辺の長さが2000になるように再縮小してからマスクを予測した.
すべての実験において,予測されたマスクを生成するために,同じ入力が各モデルに供給された.
比較のため,各データセットのグランドトゥルースマスクもレーティングのために提出された.
シングルポイント実験では,データセットごとに4000の評価ジョブを与えた(RITM,SAMシングル出力,SAM,グランドトゥルースにそれぞれ1000マスク).
インスタンスセグメンテーション実験では,合計3000ジョブ(ViTDet,SAM,グランドトゥルース)を提供した.
各データセットについて,これらのジョブはランダムな順序でキューに挿入され,そこから30人のアノテータがジョブを描いた.
レビュー研究の初期テストでは,各ジョブを5人の異なるアノテーション担当者に提供し,スコアに適度な一貫性があることを確認した.
5人のアノテーション担当者のスコアの平均標準偏差は0.83だった.
さらに,アノテーション会社は品質保証テスターを配置し,ガイドラインから極端に逸脱した結果がないか,一部の結果を抜き打ちでチェックした.
このように,今回の実験では,1つの作業(1つの画像の1つのマスクの評価)を1人のアノテーション担当者だけで完結させた.
1人のアノテータが1つのジョブに費やした平均時間は90秒で,当初の目標である30秒よりは長かったものの,7つのデータセットそれぞれについて多数の評価を収集するには十分な速度だった.


結果:
図18は,シングルポイント実験における各データセットの評価に関するヒストグラムである.
- SAMはベースラインモデル(RITMまたはViTDet)より高いスコアを得た.
- SAMは単一出力SAMより高いスコアを得る,という2つの仮説について統計的検定を実施した.
P値は,モデルスコアの平均値のペアt検定で計算し,10kサンプルのペアブートストラップ検定で補足して,平均値の差の99%信頼区間を求める.
表8は,これらの検定のp値と信頼区間である.
すべての統計検定は強く有意であり,すべての信頼区間はゼロを除く.
セグメンテーションの例として,本文の図11に,評価のヒストグラムを示す.
COCOのグランドトゥルースと比較するために,人間のレビュープロセスのテスト中に収集されたCOCOグランドトゥルースのマスクの794件の評価を追加している.
これらのマスクは,LVISの結果と同じ設定を使って評価者に提示された.
公平に比較するために,図11のLVISの結果は,各モデルとグランドトゥルースの同じ794の入力にサブサンプリングされている.
表8では,1000件の評価結果を用いて統計テストを行い,ViTDetに対するSAMのマスク品質の向上が統計的に有意であることを示している.
付録F:Dataset, Annotation, and Model Cards(データセット,アノテーション,モデルカード)

付録F.1では,SA-1Bのデータセットカードを,[39]に倣って,質問と回答のリストで提供する.
次に,付録F.2において,4章で説明したデータエンジンの最初の2段階について,CrowdWork-Sheets[30]に倣ってデータアノテーションカードを提供し,再び質問と回答のリストとする.
表9では,[75]に従い,モデルカードを提供する.
付録F.1:Dataset Card for SA1B(SA1B用データセットカード)
モチベーション:
- Q. そのデータセットはどのような目的で作られましたか?具体的なタスクがありましたか?埋めなければならない特定のギャップがありましたか?具体的な説明をお願いします.
A. 本データセットのビジョンコミュニティへの貢献は4つある.- 11M枚の画像と1.1B枚のマスクからなるデータセットを公開し,これまでのセグメンテーションデータセットとしては圧倒的に大きい.
- 公開するデータセットはプライバシー保護に配慮しており,全ての画像で顔やナンバープレートにぼかしを入れている.
- データセットは,https://ai.facebook.com/datasets/segment-anythingにある広範な利用規約の下でライセンスされている.
- このデータは,以前のデータよりも地理的に多様であり,コミュニティがより公正で公平なモデルを作ることに一歩近づくことを期待している.
- Q. データセットは誰が(例:どのチーム,研究グループ),どの団体(例:企業,機関,組織)の代理として作成しましたか?
A. このデータセットは,Meta AIのFAIRチームによって作成された.基礎となる画像は,サードパーティの写真会社から収集し,ライセンスを取得したものである. - Q. データセットの作成に資金を提供したのは誰ですか?関連する助成金がある場合は,助成者の名前と助成金の名前と番号を教えてください.
A. Meta AIはデータセットの作成に資金を提供した. - Q. 他に何かコメントはありますか?
A. いいえ.
コンポジション:
- Q. データセットを構成するインスタンスは何を表していますか(例:文書,写真,人,国)?インスタンスの種類は複数ありますか(例:映画,ユーザ,評価,人物とそれらの間の相互作用,ノードとエッジ)?説明をお願いします.
A. データセットのインスタンスは全て写真である.写真の主題は様々で,写真の共通のテーマは,場所,物,シーンなどである.写真はすべて別個のものであるが,同じ被写体を撮影した写真のセットがいくつか存在する. - Q. 全部で(適切な場合,各タイプの)インスタンスは何個ありますか?
A. 画像は11M枚である. - Q. データセットには可能な限りのインスタンスが含まれていますか,それとも,より大きな集合からのインスタンスのサンプル(必ずしもランダムではない)ですか?データセットがサンプルである場合,より大きな集合は何ですか?サンプルはより大きな集合を代表するものですか(例えば,地理的な範囲)?もしそうなら,この代表性がどのように検証・確認されたかについて説明してください.より大きな集合を代表していない場合は,その理由を記述してください(例えば,より多様なインスタンスをカバーするため,インスタンスが保留されたり入手できなかったりしたためなど).
A. データセットは,写真プロバイダーからライセンスを受けた画像で構成されている.データセットには,ライセンスされたすべてのインスタンスが含まれている.画像は写真であり,少数の例外はあるがアートワークではない.データセットには,データセット内の各画像に対して生成されたすべてのマスクが含まれる.テスト用に無作為に選んだ2k枚以下の画像は非公開とした. - Q. 各インスタンスはどのようなデータで構成されていますか?「生」データ(例:加工されていないテキストや画像),または特徴量?どちらの場合も,説明をお願いします.
A. データセットの各インスタンスは画像である.画像は,画像に写っている人の身元を保護するために,顔やナンバープレートをぼかす処理が施されている. - Q. 各インスタンスに関連するラベルやターゲットはありますか?もしあれば,説明をお願いします.
A. 各画像はマスクでアノテーションされている.マスクに関連するカテゴリやテキストはない.平均的な画像には100個以下のマスクがあり,合計で1.1B個以下のマスクがある. - Q. 個々のインスタンスから何らかの情報が欠落していますか?その場合,その情報が欠落している理由(例:入手不可能であったため)を説明した上で,説明を記述してください.意図的に削除された情報は含まれませんが,例えば,朱書きされたテキストは含まれるかもしれません.
A. はい,各画像には,写真の内容や場所を自由形式のテキストで説明する短いキャプションが付く.写真提供者との契約により,これらのキャプションを公開することはできない.しかし,データセットの地理的な分布を分析するために,論文で使用している. - Q. 個々のインスタンス間の関係は明示されていますか(例:ユーザの映画評価,ソーシャルネットワークのリンクなど)?もしそうなら,これらの関係がどのように明示されているのか説明してください.
A. いいえ.このデータセットにはインスタンス間の既知の関係は存在しない. - Q. データセットにエラー,ノイズ源,冗長性はありますか?もしあれば,その説明をお願いします.
A. エラー:マスクはセグメンテーションモデルによって生成されているため,マスクにエラーや矛盾がある可能性がある.冗長性:同じ画像は2枚とないが,同じ被写体の画像が時間的に接近して撮影されている場合がある. - Q. データセットは自己完結していますか,あるいは外部リソース(ウェブサイト,ツイート,他のデータセットなど)へのリンクや依存がありますか?外部リソースにリンクしている,または依存している場合,(a)時が経っても,それらが存在し,一定であることが保証されていますか?(b)完全なデータセット(すなわち,データセットが作成された時点で存在した外部資源を含む)の公式なアーカイブ版がありますか?(c)データセットの利用者に適用される可能性のある,外部リソースに関連する制限(例:ライセンス,料金)はありますか?すべての外部資源とそれに関連する制限事項の説明,および必要に応じてリンクや他のアクセスポイントを提供してください.
A. データセットは自己完結している. - Q. データセットには,機密とみなされる可能性のあるデータ(例えば,法的特権や医師と患者の機密によって保護されているデータ,個人の非公開の通信内容を含むデータ)が含まれていますか?もしそうなら,説明を提供してください.
A. いいえ. - Q. データセットには,直接見た場合,攻撃的,侮辱的,脅迫的,あるいは不安を引き起こす可能性のあるデータが含まれていますか?もしそうなら,その理由を説明してください.
A. 不快なコンテンツを防ぐために,2つの安全策をとっている.(1)写真は写真提供会社からライセンスを受け,写真提供会社の利用規約を満たす必要があった.我々は,ライセンスした画像からすべての不快なコンテンツがフィルタリングされるよう要請した.(2)もしユーザがデータセットの中に不快な画像を発見した場合,その画像を削除するためにsegmentanything@meta.comに報告するよう呼びかける.しかしながら,一部の画像には,多様な宗教的信条や政治的意見に焦点を当てた抗議活動やその他の集まりのシーンが含まれており,不快感を与える可能性があることが確認されている.このような画像をすべて削除するようなフィルタリングを行うことはできず,このようなコンテンツはユーザからの通報に頼っている. - Q. データセットには,(年齢別,性別など)何らかの部分母集団が特定されていますか?もしそうなら,これらの部分母集団がどのように特定されているかを説明し,データセット内のそれぞれの分布について説明してください.
A. このデータセットでは,写真に写っている人たちの部分母集団は特定されていない. - Q. データセットから直接または間接的に(すなわち,他のデータと組み合わせて),個人(すなわち,1人または複数の自然人)を特定することが可能ですか?もし可能な場合,その方法を教えてください.
A. いいえ.画像は,個人を特定できる情報を除去するために,顔ぼかしモデルを適用している.もしユーザが匿名化の問題を発見した場合,その問題と画像IDをsegment-anything@meta.comで報告してください. - Q. データセットには,何らかの形でセンシティブとみなされる可能性のあるデータ(例えば,人種や民族の出自,性的指向,宗教的信条,政治的意見,組合への加入,所在地を明らかにするデータ,金融や健康に関するデータ,生体情報や遺伝子データ,社会保障番号などの政府識別の形態,犯罪歴)が含まれていますか?もしそうなら,その説明をお願いします.
A. このデータセットには,宗教的信念,政治的意見,組合への加入を示唆するような抗議活動やその他の集まりのシーンが含まれている.しかし,データセットに含まれるすべての人の顔は,顔のぼかしによって匿名化されているため,データセットに含まれる人物を特定することは不可能である. - Q. 他に何かコメントはありますか?
A. いいえ.
コレクションプロセス:
- Q. 各インスタンスに関連するデータはどのように取得されたのですか?そのデータは,直接観察可能なものですか(例:生テキスト,映画評価),被験者から報告されたものですか(例:アンケート回答),他のデータから間接的に推測されたものですか(例:品詞タグ,年齢や言語に関するモデルベースの推測)?データが被験者から報告されたもの,または他のデータから間接的に推測されたものである場合,そのデータは検証されましたか?もしそうなら,その方法を説明してください.
A. 各画像に関連するリリースされたマスクは,当社のセグメンテーションモデルであるSAMによって自動的に推論された.モデル支援型手動アノテーションを使用して収集されたマスクは,リリースされていない.品質は5章で説明したように検証された. - Q. データを収集するために,どのようなメカニズムや手順が用いられましたか(例:ハードウェア装置やセンサー,人手によるキュレーション,ソフトウェアプログラム,ソフトウェアAPI)?これらのメカニズムや手順はどのように検証されましたか?
A. データセットに含まれる画像は,画像プロバイダーからライセンスを受けたものである.これらはすべて,カメラマンが異なるカメラで撮影した写真である. - Q. データセットがより大きな集合からのサンプルである場合,サンプリング戦略はどのようなものでしたか(例:決定論的,特定のサンプリング確率を持つ確率論的など)?
A. テスト用に,無作為に選んだ2k枚以下の画像を非公開にした.残りのライセンス画像はデータセットに含まれている. - Q. データ収集に関わった人(学生,クラウドワーカー,コントラクターなど)とその報酬(クラウドワーカーにいくら支払われたかなど)は?
A. 公開されたマスクは,SAMによって自動的に推論されたものである.モデル支援による手動アノテーションプロセスの詳細については,付録F.2のデータアノテーションカードを参照.これらのマスクは公開されないことに注意されたい. - Q. データはどのような時間枠で収集されましたか?この時間枠は,インスタンスに関連するデータの作成時間枠(例:古いニュース記事の最近のクロール)と一致しますか?そうでない場合,インスタンスに関連するデータが作成されたタイムフレームを説明してください.
A. ライセンス写真は,2022年までの幅広い年代で撮影日が異なる. - Q. 倫理的な審査が行われましたか(例えば,施設内審査委員会)?もしそうなら,結果を含むこれらの審査プロセスの説明と,支援文書へのリンクまたは他のアクセスポイントを提供してください.データセットが人に関係しない場合は,このセクションの残りの質問を省略することができます.
A. 我々は,写真に写っている人のプライバシーに関する潜在的なリスクを評価し,軽減する方法を決定するために,社内のプライバシーレビューを受けた.顔やナンバープレートをぼかすことで,写真に写っている人のプライバシーを保護している. - Q. 当該個人から直接データを収集したのですか,第三者や他の情報源(ウェブサイトなど)を介して入手したのですか?
A. 第三者である写真提供会社からライセンスを受け,データを取得した. - Q. 当該個人は,データ収集について通知されましたか?その場合,どのように通知が行われたかを説明し(またはスクリーンショットやその他の情報で示し),通知自体の正確な文言をリンクまたはその他のアクセスポイントを提供するか,またはその他の方法で再現してください.
A. 画像は,個人から必要とされる通知や同意の収集に関して適切な表明を行った第三者からライセンスを受けたものである.また,個人を特定できる情報(例:顔,ナンバープレート)はすべてぼかし処理されている.データセットのライセンス条項では,画像を特定の個人と識別したり関連付けたりすることは禁止されている. - Q. 当該個人は,データの収集と利用に同意しましたか?同意した場合は,どのように同意を求め,提供したかを説明し(またはスクリーンショットやその他の情報で示し),個人が同意した正確な文言をリンクまたはその他のアクセスポイントに提供するか,その他の方法で再現してください.
A. 画像は,個人から必要とされる通知や同意の収集に関して適切な表現を提供した第三者からライセンスを受けたものである.また,個人を特定できる情報(例:顔,ナンバープレート)は,すべての画像からぼかされている.なお,データセットライセンスに基づき,画像を特定の個人と関連付けることは禁止されている.
※8と9はほぼ同じ内容. - Q. 同意が得られた場合,同意した個人は,将来または特定の使用について同意を取り消すための仕組みを提供されましたか?もしそうであれば,その説明と,(適切であれば)そのメカニズムへのリンクまたはその他のアクセスポイントを提供してください.
A. 画像の削除については,segmentanything@meta.comまで報告されたい. - Q. データセットとその使用がデータ対象者に与える潜在的な影響についての分析(例:データ保護影響分析)が行われましたか?実施した場合は,その結果を含む分析内容の説明と,裏付けとなる文書へのリンクまたはその他のアクセスポイントを提供してください.
A. データセットに含まれる写真に含まれる人々への潜在的な影響を排除するために,識別可能な情報(顔,ナンバープレート)はぼかされている. - Q. 他に何かコメントはありますか?
A. いいえ.
前処理/クリーニング/ラベリング:
- Q. データの前処理,クリーニング,ラベリングが行われましたか(例:離散化またはバケット化,トークン化,品詞タグ付けなど,SIFT特徴抽出,インスタンスの削除,欠損値の処理)?もしそうなら,説明をお願いします.そうでない場合は,このセクションの残りの質問をスキップしてかまいません.
A. 高解像度のライセンス画像は,短辺が1500ピクセルになるようにリサイズし,写真から識別可能な個人情報(顔,ナンバープレート)を削除する処理のみを行った. - Q. 前処理/クリーニング/ラベリングされたデータに加えて,「生」データも保存されましたか(例:予期せぬ将来の使用をサポートするため)?その場合,「生」データへのリンクまたは他のアクセスポイントを提供してください.
A. いいえ.安全上の理由からデータを削除し,プライバシーを尊重するため,修正前の写真は公開していない. - Q. データの前処理/クリーニング/ラベリングに使用したソフトウェアは公開されていますか?もしそうなら,リンクや他のアクセスポイントを提供してください.
A. 顔の検出には,RetinaFace[88, 89]モデル(https://github.com/serengil/retinaface)を使用した.ナンバープレートをぼかすために使用したモデルは公開されていない.
使用例:
- Q. データセットはすでに何らかのタスクに使用されたことがありますか?もしそうなら,その説明をお願いします.
A. このデータセットは,セグメンテーションモデルであるSAMの訓練に使用された. - Q. そのデータセットを使用したあらゆる論文やシステムにリンクしているリポジトリはありますか?もしあれば,リンクやその他のアクセスポイントを教えてください.
A. いいえ.しかし,データセットのすべてのユーザは引用しなければならないので,その使用状況は引用探索機で追跡可能である. - Q. データセットはどのような(他の)タスクに使用できますか?
A. このデータセットは,大規模なセグメンテーションデータセットとなることを意図している.しかし,このデータセットに追加的なアノテーションを集めることを研究コミュニティに呼びかける. - Q. データセットの構成や収集方法,前処理/クリーニング/ラベリング方法について,将来の利用に影響を与えそうなことはありますか?例えば,個人または集団の不当な扱い(例:ステレオタイプ,サービスの質の問題)やその他のリスクや害(例:法的リスク,金銭的害)をもたらしかねない利用を避けるために,データセット利用者が知る必要がありますか?もしそうなら,説明をお願いします.これらのリスクや害を軽減するために,データセットの利用者ができることはありますか?
A. 我々のデータセットのおおよその地理的・所得的なカバー率については,6章で分析している.現時点では,我々のデータセットは,一般に公開されているデータセットの多くよりも代表的であると信じている.我々は,すべてのグループにわたるパリティを持っていないことを認め,このデータセットを使用してモデルが学んだ潜在的なバイアスに留意することをユーザに奨励する. - Q. データセットを使用すべきでないタスクはありますか?もしあれば,その説明をお願いします.
A. 禁止されている使用例を含むデータセットの完全な使用条件は,https://ai.facebook.com/datasets/segment-anythingにある. - Q. 他に何かコメントはありますか?
A. いいえ.
配布:
- Q. データセットは,データセットが作成された主体(例:企業,機関,組織)以外の第三者に配布されるのでしょうか?もしそうなら,説明を提供してください.
A. データセットは研究コミュニティのために利用される予定である. - Q. データセットはどのように配布されるのですか(例:ウェブサイト上のtarball,API,GitHubなど)?データセットにはデジタルオブジェクト識別子(DOI:Digital Object Identifier)がありますか?
A. データセットはhttps://ai.facebook.com/datasets/segment-anythingで公開されている. - Q. データセットはいつ配布されるのですか?
A. データセットは2023年に公開される予定である. - Q. データセットは,著作権やその他の知的財産権(IP)ライセンス,および/または適用される利用規約(ToU:Terms of Use)のもとで配布されるのでしょうか?もしそうなら,このライセンスとToUについて説明し,関連するライセンス条項やToUへのリンクやその他のアクセスポイントを提供するか,またはその他の方法で再現し,これらの制限に関連する料金も提供してください.
A. はい.データセットのライセンス契約と使用条件は,https://ai.facebook.com/datasets/segment-anythingにある.ユーザは,データセットをダウンロードまたは使用する前に,使用条件に同意する必要がある. - Q. 第三者がインスタンスに関連するデータに対してIPベースまたはその他の制限を課したことがありますか?もしそうなら,これらの制限について説明し,関連するライセンス条項,およびこれらの制限に関連する手数料へのリンクまたはその他のアクセスポイントを提供するか,またはその他の方法で再現してください.
A. SA-1Bデータセットの使用に関する完全な使用条件と制限は,https://ai.facebook.com/datasets/segment-anythingに記載されている. - Q. データセットまたは個々のインスタンスに,輸出規制またはその他の規制上の制限が適用されていますか?もしそうなら,これらの制限を説明し,リンクまたは他のアクセスポイントを提供するか,または他の方法でサポートドキュメントを複製してください.
A. SA-1Bデータセットのライセンスと使用に関する制限は,https://ai.facebook.com/datasets/segment-anythingにある. - Q. 他に何かコメントはありますか?
A. いいえ.
メンテナンス:
- Q. データセットのサポート,ホスティング,メンテナンスは誰が行うのですか?
A. データセットは,https://ai.facebook.com/datasets/segment-anythingでホストされ,Meta AIによって管理される. - Q. データセットの所有者/キュレーター/管理者に連絡する方法(メールアドレスなど)は?
A. segment-anything@meta.comにメールを送ってください. - Q. 誤植はないのでしょうか?もしあれば,リンクなどアクセスポイントを教えてください.
A. いいえ. - Q. データセットは更新されるのでしょうか(例:ラベリングエラーの修正,新しいインスタンスの追加,インスタンスの削除など)?もしそうなら,どのくらいの頻度で,誰が,どのようにデータセット利用者に更新を伝えるのか(例:メーリングリスト,GitHub)説明してください.
A. SA-1Bを用いた研究の再現性を高めるため,更新は報告された画像を削除することのみとなる. - Q. データセットが個人に関するものである場合,そのインスタンスに関連するデータの保持に適用できる制限がありますか(例えば,該当する個人は,自分のデータが一定期間保持され,その後削除されることを知らされていましたか)?その場合,これらの制限について説明し,どのように実施されるかを説明してください.
A. データ保持の制限はない.人物の画像から個人を特定できる情報を削除する措置をとった.ユーザは,削除の可能性があるコンテンツをsegment-anything@meta.comで報告することができる. - Q. データセットの旧バージョンは引き続きサポート/ホスト/メンテナンスされるのでしょうか?もしそうなら,その方法を記述してください.もしそうでないなら,データセットの消費者にどのようにその廃棄を伝えるか説明してください.
A. いいえ.更新は有害なコンテンツを削除するためにのみ行われるため,古いバージョンをコンテンツとともに維持することはない. - Q. 他の人がこのデータセットを拡張/補強/構築/貢献したい場合,そのための仕組みはありますか?もしあれば,その説明をお願いします.これらの貢献は検証されるのでしょうか?もしそうなら,その方法を説明してください.そうでない場合は,その理由を教えてください.データセット利用者にこれらの貢献を伝達/配布するためのプロセスはありますか?もしそうなら,その説明をお願いします.
A. 我々は,ユーザがSA-1Bのためにさらなるアノテーションを収集することを推奨する.アノテーションを作成したユーザは,そのアノテーションをホストし配布する責任を負う. - Q. 他に何かコメントはありますか?
A. いいえ.
付録F.2:Data Annotation Card(データアノテーションカード)
タスクフォーミュレーション:
- Q. あなたのタスクの主観的な側面はどのようなものですか?
A. 画像に存在するオブジェクトのセグメンテーションは,本質的に主観的なタスクである.例えば,あるアノテータは2つのブーツを1つのマスクとしてセグメンテーションするが,別のアノテータはそれぞれのブーツを別々にセグメンテーションすることがある.また,アノテータのスキルによって,マスクの品質や画像あたりのマスクの枚数も異なる.このような主観的な側面はあるものの,完全性よりもデータの多様性に主眼を置き,マスク単位でアノテーションを行うため,効率的なアノテーションが可能であると考え,タスクに取り組んだ. - Q. アノテータについて,どのような前提があるのでしょうか?
A. アノテータはフルタイムでアノテーションタスクに取り組んだが,減少率は非常に少なかった.そのため,定期的にアノテーション担当者にフィードバックしたり,質問に答えたりして,アノテーション担当者を育成することができた.具体的には,(1)本作業の目的を明確に理解し,タスクのビジュアルやビデオ記録を含む明確なガイドラインを提供することで,アノテーション担当者がタスクを理解し,合理的に実行するのに十分な文脈を得た.(2)目的と主要な結果を共有し,アノテーション担当者と毎週ミーティングを行うことで,アノテーション担当者が時間の経過とともにアノテーションの質と量を向上させる可能性が高くなった. - Q. タスク命令の具体的な文言はどのように選んだのですか?アノテーションの命令や表現が明確であることを確認するために,どのような工夫をされたのでしょうか?
A. 研究チームは30回のアノテーション作業を行い,アノテーションツールの使用上の明らかな問題点を特定し,複雑なケースへの対処方法を共同で決定し,ガイドラインを改良した.研究チームは毎週アノテーション担当者と会い,フィードバックセッションを行った.研究チームがタスクを実行するビデオをアノテータとライブで共有し,その後,質疑応答が行われた.アノテータは,フィードバックセッション中と非同期で,不明な点をフィードバックすることができた. - Q. あなたのタスクがアノテータにもたらすリスクがあるとすれば,それはどのようなものですか?
A. 確認されたリスクはない.画像は,アノテーションの前に,好ましくないコンテンツがないかフィルタリングされた. - Q. アノテータに提供された正確な命令はどのようなものですか?
A. 大まかな命令のみである.画像から,可能性のあるすべてのオブジェクトをセグメンテーションすることを目指す.アノテータは,識別可能なすべてのオブジェクトに対してマスクを生成する.オブジェクトは,インタラクティブなセグメンテーションツールを使って,フォアグラウンド/バックグラウンドの修正クリックでマスクの一部を追加/削除するか,オブジェクトの周囲にバウンディングボックスを描くことでセグメンテーションすることができる.マスクは,ピクセル精度の高いツールを使って改良することができる.
アノテーションの選択:
- Q. 優遇されるべき視点というのはあるのでしょうか?もしそうなら,どのようにしてそのような視点を探し出したのでしょうか?
A. 他のビジョンアノテーションに携わったことのあるアノテータと一緒に仕事をすることにした. - Q. 含めると害になる視点はありますか?その場合,どのようにそれらの視点を選別したのでしょうか?
A. いいえ. - Q. あなたのタスクのアノテータを選ぶために,社会人口統計学的特性が使われましたか?もしそうなら,そのプロセスを詳しく教えてください.
A. いいえ. - Q. アノテータプールに関する社会人口統計の集計がある場合は,その内容を教えてください.アノテータの社会人口統計学的特性が,データのアノテーションに影響を与えたと考える理由はありますか?その理由,またはそうでない理由を教えてください.
A. 我々は130人のアノテーターと仕事をした.アノテータはすべてケニアに在住していた.アノテータの社会人口学的特性がアノテーションのデータに重要な影響を与えたとは考えていない. - Q. データセットの使用目的,およびこのデータセットで学習したモデルによって影響を受ける可能性のある個人とコミュニティについて考慮すること.これらのコミュニティはアノテータープールに含まれていますか?
A. Segment Anything 1B (SA-1B) データセットは,研究目的でのみ使用される.SA-1Bデータセットは,6章で説明するように,最も地理的に多様なセグメンテーションデータセットの1つである.また,6章では,このデータセットで学習したモデルの責任あるAI軸を分析する.
プラットフォームとインフラの選択:
- Q. どのようなアノテーションプラットフォームを利用されたのですか?どのような点を考慮してこのプラットフォームを選択したのでしょうか?選択したプラットフォームは,アノテータープールについて説明した要件を十分に満たしていましたか?また,満たされていない点はありますか?
A. 我々は,独自のアノテーションプラットフォームを使用した. - Q. アノテータとのコミュニケーションを円滑にするために,あなたが選んだプラットフォームが提供するコミュニケーションチャンネルがあるとすれば,それは何ですか?このコミュニケーションチャネルは,アノテーションプロセスやアノテーションの結果にどのような影響を与えたのでしょうか?
A. 我々はアノテーションを手作業で確認し,週単位でアノテータとフィードバックを共有した.よくある間違いや矛盾,それに対応する修正点を伝えた.また,アノテーションQAチームが毎日,アノテーションの改善点をフィードバックしている.週1回のフィードバックセッション以外でも,アノテーション担当者はスプレッドシートとチャットグループにアクセスし,研究チームとのコミュニケーションを円滑にした.このプロセスにより,アノテーションの平均的なスピードと品質が大幅に改善された. - Q. アノテータの報酬はいくらでしたか?報酬を決定する際に,何か特定の給与基準を考慮しましたか?もしそうなら,説明してください.
A. アノテータの報酬は,ベンダーが設定した時給で支払われた.ベンダーはBコーポレーションに認定されている.
データセットの解析と評価:
- Q. アノテーションの品質をどのように定義し,構築したデータセットでどのように品質を評価したのでしょうか?
A. アノテータは,まず訓練に参加した.ベンダーが実施する1日の訓練に参加し,訓練キューにある大量の例文にアノテーションをつけるよう依頼された.アノテータは,ベンダーのQAチームが研究チームと協力して,アノテータのマスクの品質を手動でチェックした後,訓練から本番へと移行した.平均して,アノテータは卒業するまでに1週間訓練に費やされた.生産品質評価も同様のプロセスで行われた.ベンダーQAチームと研究チームは,毎週手動でアノテーションを確認し,毎週フィードバックを共有した. - Q. 不一致のパターンについて分析を行ったことがありますか?その場合,どのような分析を行い,主な結果はどのようなものだったのでしょうか?不一致の潜在的な原因を分析したのですか?
A. アノテータとの週1回のミーティングで,よくある間違いを指摘した. - Q. アノテータの回答は,データセットで公開された最終的なラベルとどのような関係があるのでしょうか?
A. アノテーションは,SAMモデルの初期バージョンの訓練にのみ使用されたもので,現在のところ公開する予定はない.
データセットのリリースとメンテナンス:
- Q. このデータセットのアノテーションが時間の経過とともに変化する可能性があると考える根拠がありますか?データセットを更新する予定はありますか?
A. いいえ.不快な画像を削除する以外はない. - Q. もし変更された場合,データセットの実用性に影響を与える可能性のある条件や定義はありますか?
A. 我々はないと考えている. - Q. データセットがどのように利用されるかを追跡したり,制限をかけたり,その他の方法で影響を与えようとするのですか?もしそうなら,どのように?
A. SA-1Bデータセットは,特定の研究目的での使用を許可し,研究者を保護するライセンス契約に基づいて公開される予定である.研究者がデータセットにアクセスするには,ライセンス契約の条件に同意する必要がある. - Q. データの外部化の方法について,アノテータは知らされていましたか?データセットに変更があった場合,その旨は知らされるのでしょうか?
A. いいえ.今のところ手動アノテーションを公開する予定はない. - Q. アノテータがデータセットから自分のデータを取り下げることを後で選択できるようなプロセスはありますか?もしあれば,詳細を教えてください.
A. いいえ.
付録G:Annotation Guidelines(アノテーションガイドライン)
図19と図20に,マスクの品質を人間が確認するためのアノテーションに与えられた完全なガイドラインを示す.


参考:Segment Anythingの解説スライド・動画
Segment Anythingの解説スライドです.
Segment Anythingの解説動画です.
まとめ
Segment Anythingの日本語訳を紹介しました.
Meta(旧Facebook)の画像セグメンテーションモデル「Segment Anything Model(SAM)」がわかりました.
AIのプログラミング言語「C++/Python言語」を学べるおすすめのWebサイトを知りたいあなたはこちらからどうぞ.
独学が難しいあなたは,AIを学べるオンラインプログラミングスクール3社で自分に合うスクールを見つけましょう.後悔はさせません!
国内・海外のAIエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ. こういった悩みにお答えします. こういった私が解説していきます. 国内・海外のAIエンジニアのおすすめ求人サイト(転職エージェント)を紹介します. AIエンジニアになるためには,主にC++/Pytho ... 続きを見る
国内・海外のAIエンジニアのおすすめ求人サイト【転職エージェント】【C++/Python言語】
国内・海外のプロンプトエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ.
{kind=link}