
Tomasz Tunguzの「AI Design Patterns」の日本語訳を教えて!
こういった悩みにお答えします.
本記事の信頼性
- リアルタイムシステムの研究歴12年.
- 東大教員の時に,英語でOS(Linuxカーネル)の授業.
- 2012年9月~2013年8月にアメリカのノースカロライナ大学チャペルヒル校(UNC)コンピュータサイエンス学部で客員研究員として勤務.C言語でリアルタイムLinuxの研究開発.
- プログラミング歴15年以上,習得している言語: C/C++,Python,Solidity/Vyper,Java,Ruby,Go,Rust,D,HTML/CSS/JS/PHP,MATLAB,Verse(UEFN), Assembler (x64,aarch64).
- 東大教員の時に,C++言語で開発した「LLVMコンパイラの拡張」,C言語で開発した独自のリアルタイムOS「Mcube Kernel」をGitHubにオープンソースとして公開.
- 2020年1月~現在はアメリカのノースカロライナ州チャペルヒルにあるGuarantee Happiness LLCのCTOとしてECサイト開発やWeb/SNSマーケティングの業務.2022年6月~現在はアメリカのノースカロライナ州チャペルヒルにあるJapanese Tar Heel, Inc.のCEO兼CTO.
- 最近は自然言語処理AIとイーサリアムに関する有益な情報発信や,Unreal Editor for Fortnite(UEFN)でゲーム開発に従事.
- (AI全般を含む)自然言語処理AIの論文の日本語訳や,AIチャットボット(ChatGPT,Auto-GPT,Gemini(旧Bard)など)の記事を50本以上執筆.アメリカのサンフランシスコ(広義のシリコンバレー)の会社でChatGPT/Geminiを訓練するプロンプトエンジニア・マネージャー・Quality Assurance(QA)の業務委託の経験あり.
- (スマートコントラクトのプログラミングを含む)イーサリアムや仮想通貨全般の記事を200本以上執筆.イギリスのロンドンの会社で仮想通貨の英語の記事を日本語に翻訳する業務委託の経験あり.
- UEFNで10本以上のゲームを開発し,フォートナイト上で公開(Fortnite,Fortnite.GG).
こういった私から学べます.
AIのプログラミング言語「C++/Python言語」を学べるおすすめのWebサイトを知りたいあなたはこちらからどうぞ.

独学が難しいあなたは,AIを学べるオンラインプログラミングスクール3社で自分に合うスクールを見つけましょう.後悔はさせません!

国内・海外のAIエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ. こういった悩みにお答えします. こういった私が解説していきます. 国内・海外のAIエンジニアのおすすめ求人サイト(転職エージェント)を紹介します. AIエンジニアになるためには,主にC++/Pytho ... 続きを見る

国内・海外のAIエンジニアのおすすめ求人サイト【転職エージェント】【C++/Python言語】
国内・海外のプロンプトエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ.

2024年2月5日に公開されたTomasz Tunguzの「AI Design Patterns」の日本語訳を紹介します.
Tomasz Tunguzは,Venture Capitalist at Theoryで働いているVC界隈で有名な方です.
AIのデザインパターンは,AIアプリケーションを開発する際に参考になることがわかります.
いわゆるソフトウェア開発におけるデザインパターンのAI版ですね!
※図表を含む論文の著作権はTomasz Tunguzに帰属します.
また,AI Design Patternsに続く以下の記事の日本語訳も紹介します.
目次
Tomasz Tunguzの「AI Design Patterns」(AIのデザインパターン)の日本語訳
AIの現状とアプリケーションの作り方を研究しているうちに,AI製品のデザインパターンがいくつか浮かび上がってきた.
これらのデザインパターンは単純なメンタルモデルである.
これらのパターンは,現在AIアプリケーションをどのように設計しているのか,また将来的にどのコンポーネントが重要になるのかを理解するのに役立つ.

最初のデザインパターンは,AIクエリ・ルータである.
ユーザがクエリを入力すると,そのクエリはルータに送られ,ルータは入力を分類する分類器である.
認識されたクエリは,より正確で応答性が高く,運用コストが低い傾向にある,小さな言語モデルにルーティングされる.
クエリが認識されない場合,大規模言語モデルがそれを処理する.
LLMは運用コストがはるかに高いが,より多様なクエリに対する回答を返すことに成功している.
このようにして,AI製品はコスト,パフォーマンス,ユーザ体験のバランスをとることができる.

2つ目のデザインパターンは,訓練のためのものである.
モデルはデータ(実世界や合成,あるいは別のマシンによって作られたもの)で訓練され,次に評価のために送られる.
モデルの素晴らしさを示すゴールドスタンダードがないため,その評価は今日多くの議論を呼んでいる.
これらのモデルを評価する際の課題は,入力が非常に多様であることである.
2人のユーザが同じ質問を同じようにすることはまずない.
出力はまた,これらのアルゴリズムの非決定性とカオス的性質の結果として,かなり変動する可能性がある.
敵対的モデルはAIのテストと評価に使われる.
敵対的モデルは,モデルにストレスを与えるために何十億ものテストを提案することができる.
敵対的モデルは,ターゲットモデルとは異なる強みを持つように訓練することができる.
優れたチームメイトやライバルが我々のパフォーマンスを向上させるように,敵対的モデルはAIにとってその役割を果たすだろう.
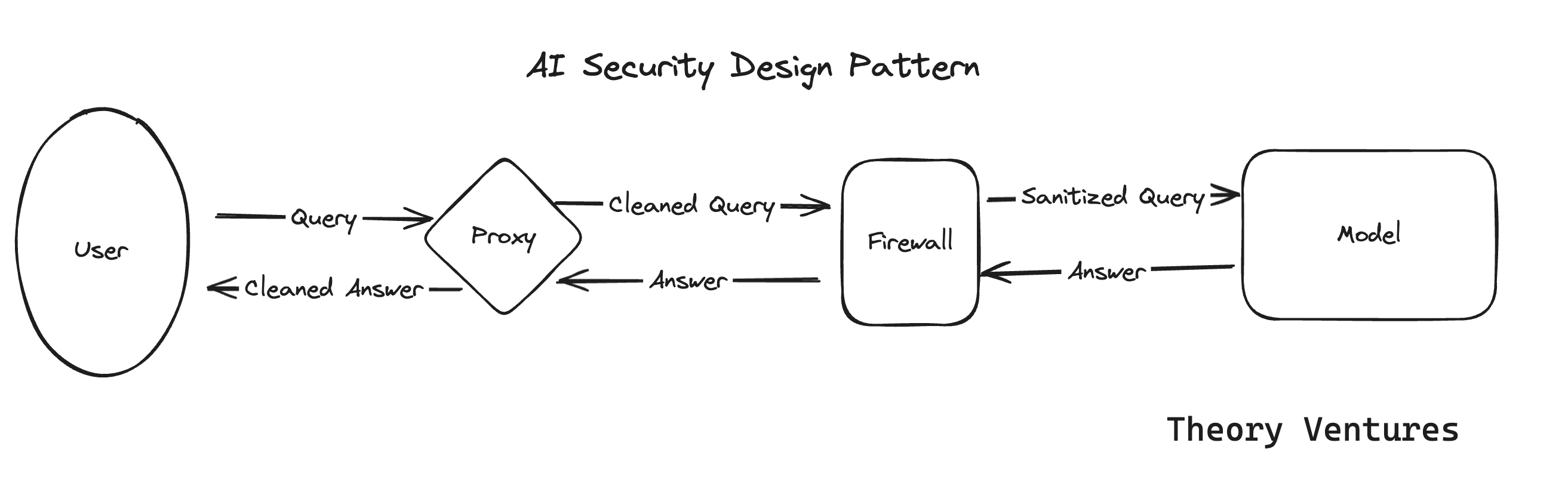
LLMの中核となるセキュリティには2つのコンポーネントがある.
ユーザコンポーネント,ここではプロキシと呼ばれるものと,モデルをラップするファイアウォールである.
プロキシは,ユーザのクエリを送信時と受信時の両方でインターセプトする.
プロキシは個人情報(PII:Personally Identifiable Information)と知的財産(IP:Intellectual Property)を排除し,クエリを記録し,コストを最適化する.
ファイアウォールは,モデルとそれが使用するインフラを保護する.
我々は,人間がどのようにモデルを操作し,その基礎となる訓練データ,その基礎となる機能,そして悪意ある行為のためのオーケストレーションを明らかにすることができるかについて,今日,最低限の理解を持っている.
しかし,我々はこれらの強力なモデルが脆弱であることを知っている.
スタック内には他のセキュリティレイヤも存在するが,クエリパスという観点からは,これらが最も重要である.

AI開発者のデザインパスにおける,現在のデザインパターンの最後のものを紹介する.
開発者のマシンは,Endpoint Detection & Response(EDR)で保護され,モデルの訓練に使用されるデータや基礎となるモデルが汚染されないようにする.
開発者のコードはCICDシステムに送られる.
CICDシステムは,署名(Sig Verification)を使ってモデルとデータが正しいかどうかをチェックする.
今日,ほとんどのソフトウェアの署名は検証されている.
しかし,AIモデルは違う.
また,大規模言語モデルは,それが期待通りに実行されることを保証するために,テストハーネス(一連のテスト)の対象となる.
ライブトラフィックからの実際のユーザからの問い合わせが,ハーネスに反映される.
これらのテストに合格すると,モデルは製品にプッシュされる.
これらは,大規模言語モデルがどのように構築され,保護され,デプロイされるかについての,我々の現在の4つのメンタルモデルである.
これらは,我々が暗い部屋で描こうとしている象の足のスケッチです.
他のデザインパターンや,現在のデザインパターンに対する改良点についてのアイデアがありましたら,ぜひご連絡されたい.
我々は,他の人たちを助けるためにこれらを改善したいと思っている.
Vincent Kocの「Generative AI Design Patterns: A Comprehensive Guide」(生成AIのデザインパターン: 包括的ガイド)の日本語訳
サブタイトル「大規模言語モデル(LLMs:Large Language Models)を扱うための参照アーキテクチャパターンとメンタルモデル」
The Need For AI Patterns(AIのパターンの必要性)
我々は皆,新しいものを作るときには,試行錯誤を重ねた手法やアプローチ,パターンを採用する.
この言葉は,ソフトウェアエンジニアリングに携わる者にとっては非常に正しい.
しかし,生成AIや人工知能そのものについては,そうではないかもしれない.
生成AIのような新しいテクノロジーでは,我々のソリューションの根拠となる,よく文書化されたパターンが不足している.
ここでは,数え切れないほどのLLMの製品実装の評価に基づいて,生成AIのための一握りのアプローチとパターンを共有する.
これらのパターンの目的は,コスト,レイテンシ,幻覚など,生成AIの実装に関するいくつかの課題を軽減し,克服するのを助けることである.
List of Patterns(パターン一覧)
1) Layered Caching Strategy Leading To Fine-Tuning(ファインチューニングにつながるレイヤードキャッシング戦略)

ここでは,大規模言語モデルにキャッシュ戦略とサービスを導入する際に,コスト,冗長性,訓練データなどの要素を組み合わせて解決している.
このような初期結果をキャッシュすることで,システムはその後のクエリでより迅速に回答を提供し,効率を高めることができる.
さらに,十分なデータを得た後のファインチューニングレイヤでは,このような初期のやりとりからのフィードバックを使って,より特化したモデルを改良していく.
この特化型モデルは,プロセスを合理化するだけでなく,AIの専門知識を特定のタスクに合わせて調整するため,カスタマーサービスやパーソナライズされたコンテンツ作成など,精度と適応性が最も重要な環境において非常に効果的である.
GPTCacheのようなビルド済みのサービスや,Redis,Apache Cassandra,Memcachedのような一般的なキャッシング・データベースを使って自分で作ることもできる.
サービスを追加する際には,必ずレイテンシを監視・測定されたい.
2) Multiplexing AI Agents For A Panel Of Experts(専門家パネルのためのAIエージェントの多重化)

特定のタスクに特化した複数の生成AIモデル「エージェント」が,それぞれがその領域のスペシャリストであり,クエリに対処するために並列して動作するエコシステムを想像してみてほしい.
この多重化戦略により,多様な回答が可能になり,それらが統合されて包括的な答えが提供される.
この設定は,問題の異なる側面が異なる専門知識を必要とするような複雑な問題解決シナリオに理想的で,大きな問題の一面にそれぞれが取り組む専門家チームのようなものである.
GPT-4のような大きなモデルは,コンテキストを理解し,これを特定のタスクや情報要求に分解し,小さなエージェントに渡す.
エージェントは,Phi-2やTinyLlamaのような小さな言語モデルで,特定のタスク,特定のツールへのアクセス,またはGPTやLlamaのような汎化されたモデルで,特定の性格,コンテキストのプロンプト,関数の呼び出しについて訓練されている.
3) Fine-Tuning LLM’s For Multiple Tasks(複数のタスクのためにLLMをファインチューニング)

ここでは,大規模言語モデルを単一のタスクではなく,複数のタスクで同時にファインチューニングする.
これは,異なるドメイン間での知識とスキルの確実な移行を促進し,モデルの汎用性を高めるアプローチである.
このマルチタスク学習は,バーチャルアシスタントやAIを搭載した研究ツールなど,様々なタスクを高い能力で処理する必要があるプラットフォームには特に有効である.
これにより,複雑な領域の訓練とテストのワークフローを簡素化できる可能性がある.
LLMを訓練するためのリソースやパッケージには,DeepSpeedやHugging FaceのTransformerライブラリの訓練関数などがある.
4) Blending Rules Based & Generative(ルールベースと生成の融合)
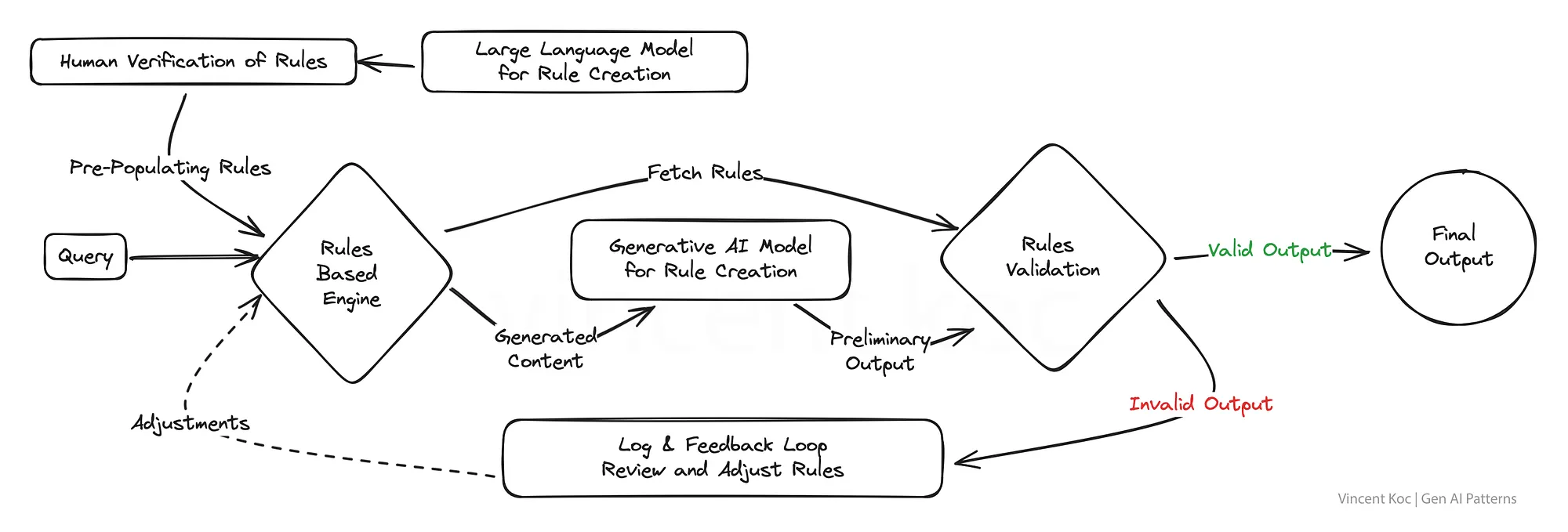
既存のビジネスシステムや組織のアプリケーションの多くは,いまだにルールベースである.
生成的なものとルールベースのロジックの構造化された正確さを融合させることで,このパターンは創造的でありながらコンプライアンスに準拠したソリューションを生み出すことを目指している.
これは,アウトプットが厳しい基準や規制を遵守しなければならない業界にとって強力な戦略であり,AIが望ましいパラメータの範囲内にとどまることを保証しながら,革新とエンゲージメントを実現することができる.
この良い例は,電話IVRシステムや従来の(非LLMベースの)チャットボットのインテントとメッセージフローを生成することである.
5) Utilizing Knowledge Graphs with LLM’s(LLMで知識グラフを活用)
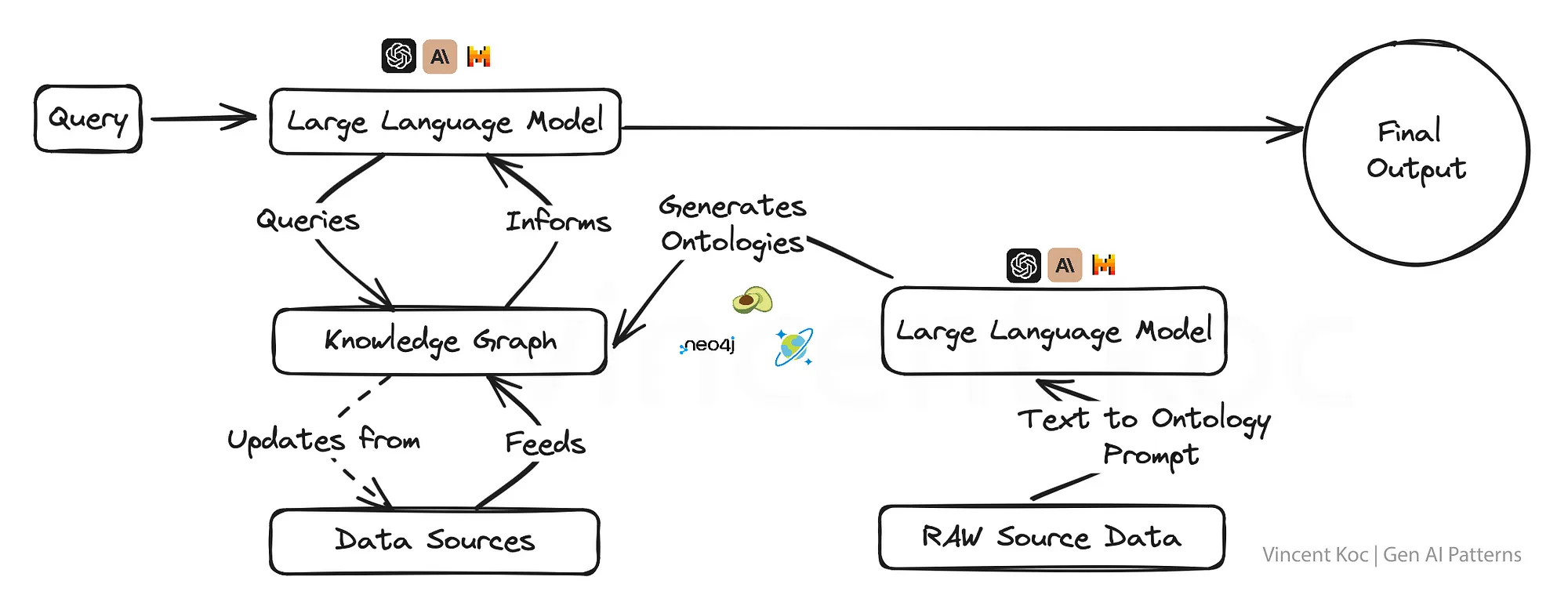
知識グラフを生成AIモデルと統合することで,事実指向のスーパーパワーが得られ,コンテキストを認識するだけでなく,より事実に基づいた正しいアウトプットが可能になる.
このアプローチは,教育コンテンツ制作,医療アドバイス,あるいは誤情報が重大な結果をもたらす可能性のあるあらゆる分野など,真実性と正確性が譲れないアプリケーションにとって極めて重要である.
知識グラフとグラフオントロジー(グラフの概念の集合)は,複雑なトピックや組織的な問題を構造化されたフォーマットに分割し,深いコンテキストを持つ大規模な言語モデルの土台とすることを可能にする.
言語モデルを使用して,JSONやRDFなどのフォーマットでオントロジーを生成することもできる.
知識グラフに利用できるサービスには,ArangoDB,Amazon Neptune,Azure Cosmos DB,Neo4jなどのグラフデータベースサービスがある.
また,Google Enterprise Knowledge Graph API,PyKEEN Datasets,Wikidataなど,より広範な知識グラフにアクセスするためのデータセットやサービスもある.
6) Swarm Of AI Agents(AIエージェントの群)
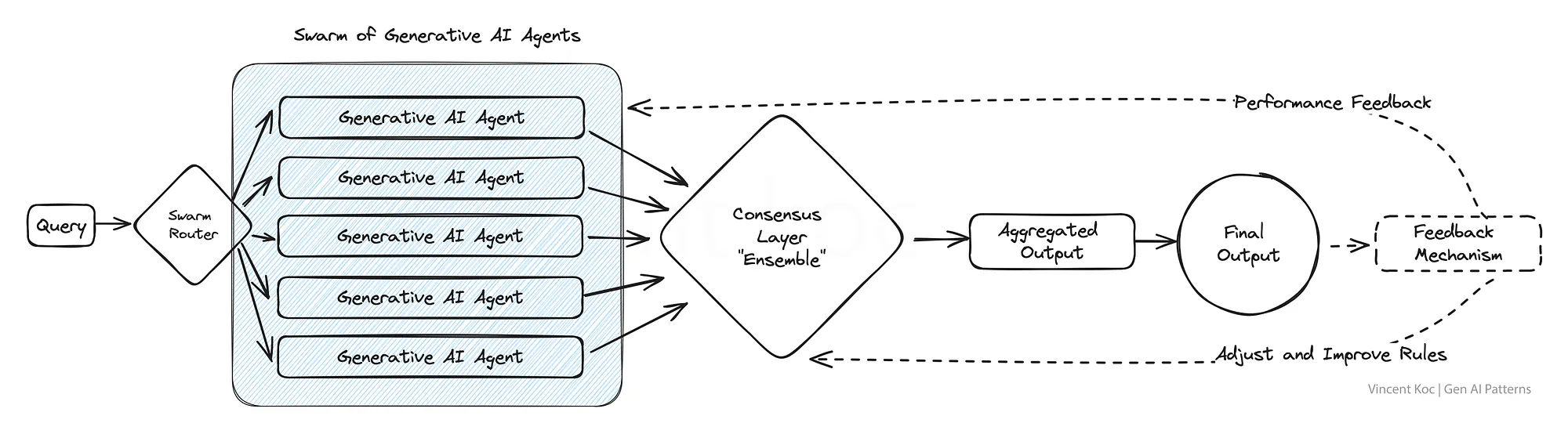
自然の大群や群れからヒントを得たこのモデルは,問題に集団で取り組む多数のAIエージェントを採用し,それぞれが独自の視点で貢献する.
結果として得られる集約されたアウトプットは,個々のエージェントが達成しうるものを凌駕する,集合知の一形態を反映している.
このパターンは,創造的なソリューションの幅を必要とするシナリオや,複雑なデータセットをナビゲートする場合に特に有利である.
例えば,複数の「専門家」の視点から研究論文をレビューしたり,不正行為からオファーまで,一度に多くのユースケースについて顧客とのやり取りを評価したりすることができる.
このような集合的な「エージェント」を取り込み,すべてのインプットを組み合わせる.
大容量の群の場合,エージェントとサービス間のメッセージを処理するために,Apache Kafkaのようなメッセージングサービスのデプロイを検討することができる.
7) Modular Monolith LLM Approach With Composability(コンポーザビリティを備えたモジュラー・モノリスLLMアプローチ)
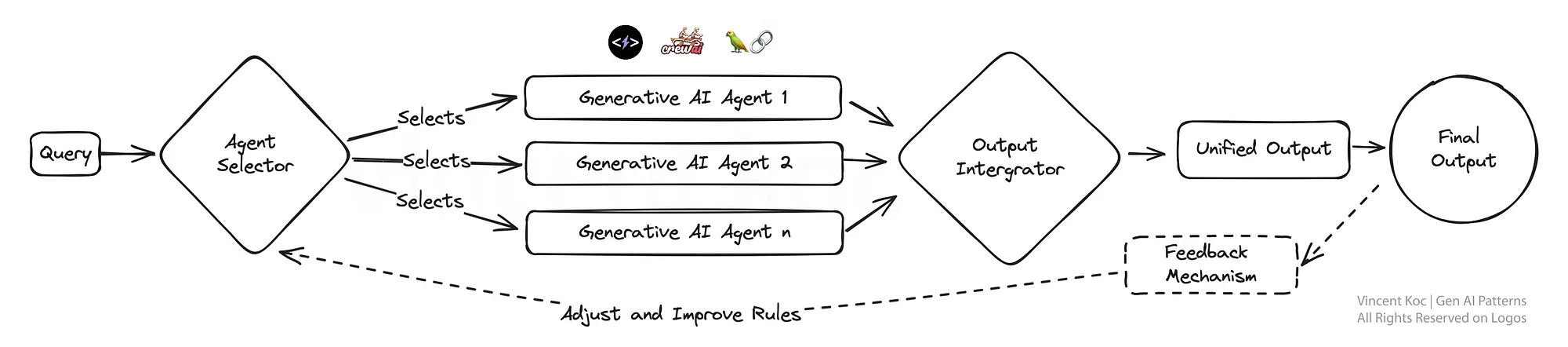
このデザインは,最適なタスクパフォーマンスのために動的に再構成できるモジュール式AIシステムを特徴とし,適応性を追求している.
これはスイス軍用ナイフのようなもので(※訳注:便利という意味),必要に応じて各モジュールを選択し,起動させることができるため,さまざまな顧客とのやり取りや製品ニーズに対してオーダーメイドのソリューションを必要とするビジネスにとって非常に効果的である.
各エージェントとそのツールを開発するために,様々な自律エージェントフレームワークとアーキテクチャの使用をデプロイすることができる.
フレームワークの例としては,CrewAI,LangChain,Microsoft Autogen,SuperAGIなどがある.
セールス・モジュール・モノリスの場合,1つは見込み客の開拓,1つは予約の処理,1つはメッセージの生成,もう1つはデータベースの更新に特化したエージェントとなる.
将来的に,専門のAI企業から特定のサービスが提供されるようになれば,与えられた一連のタスクやドメイン固有の問題に対して,モジュールを外部やサードパーティのサービスと交換することができる.
8) Approach To Memory Cognition For LLM’s(LLMのための記憶認知へのアプローチ)
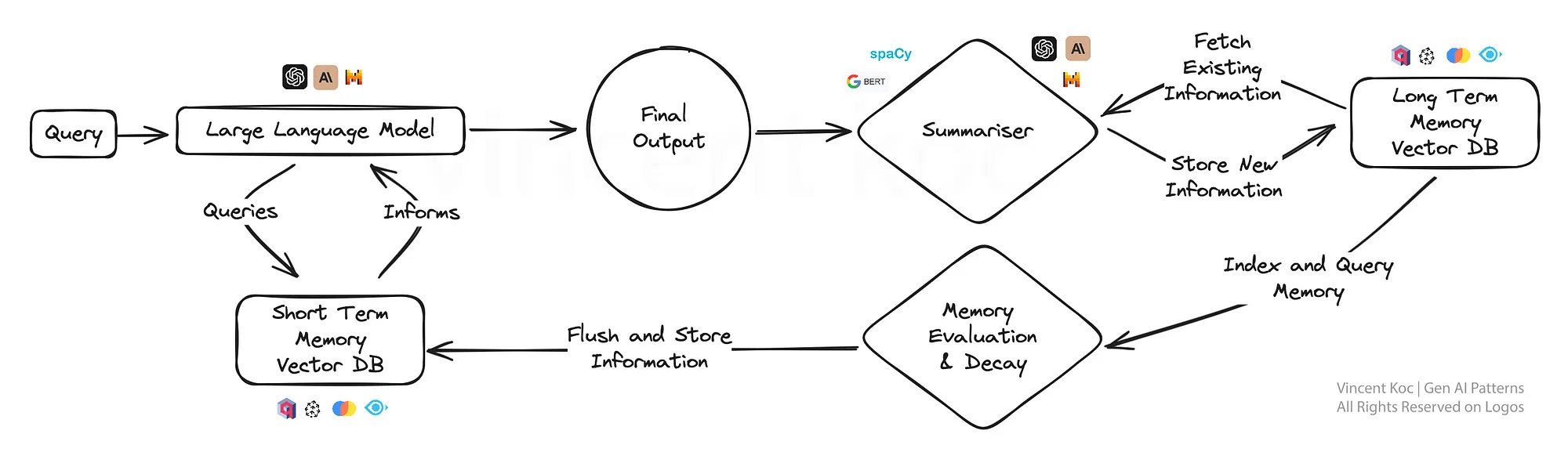
このアプローチは,AIに人間のような記憶の要素を導入し,モデルが以前のやりとりを思い出し,それを基に,より微妙な反応をすることを可能にする.
継続的な会話や学習シナリオには特に有効で,AIは専用パーソナルアシスタントや適応学習プラットフォームのように,時間の経過とともにより深い理解を深めていく.
記憶認知のアプローチは,時間の経過とともに重要な出来事や議論をベクトルデータベースにまとめ,保存することで発展させることができる.
要約の計算量を低く抑えるために,spaCyのような小規模なNLPライブラリを使った要約や,かなりの量を扱う場合はBART言語モデルを活用することができる.
使用されるデータベースはベクトルベースであり,短期記憶をチェックするプロンプト段階での検索は,重要な「事実」を見つけるために類似検索を使用する.
実用的なソリューションに興味のある方には,MemGPTと呼ばれる同様のパターンに従ったオープンソースのソリューションがある.
9) Red & Blue Team Dual-Model Evaluation(Red&Blueチームのデュアルモデル評価)
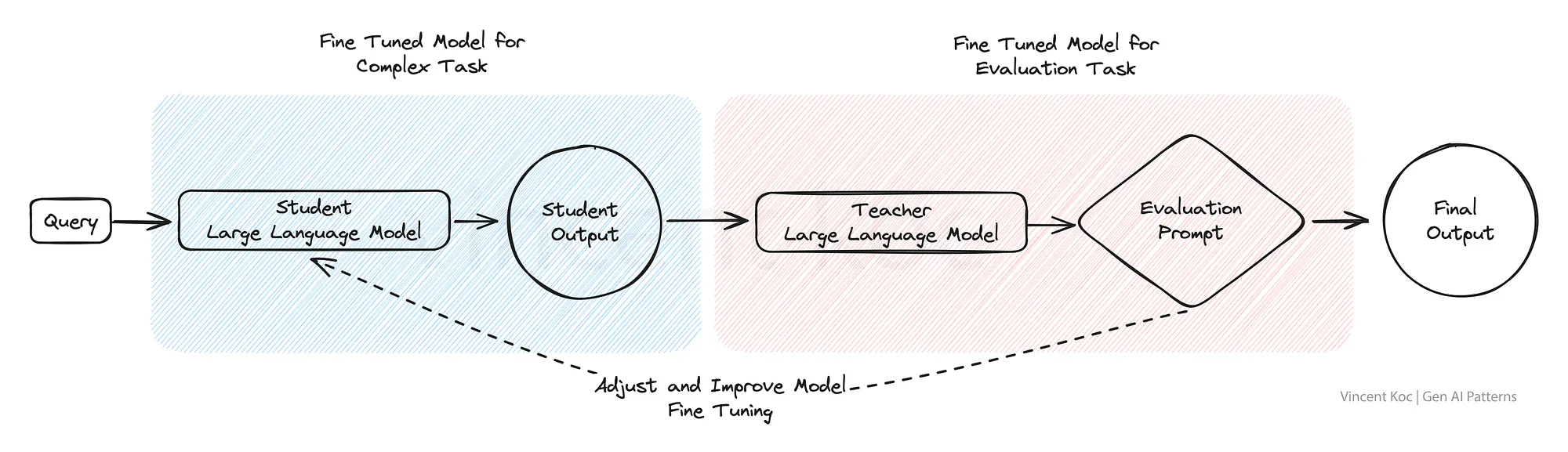
RedとBlueのチーム評価モデルでは,1人のAIがコンテンツを生成し,もう1人がそれを批判的に評価する.
これは,厳密な査読プロセスに似ている.
この二重モデルの設定は品質管理に優れているため,ニュースアグリゲーションや教材制作など,信頼性と正確性が重要なコンテンツ生成プラットフォームで大いに活用できる.
このアプローチは,複雑なタスクに対する人間のフィードバックの一部を,人間のレビュープロセスを模倣し,複雑な言語シナリオやアウトプットを評価する結果を洗練させるために,ファインチューニングされたモデルで置き換えるために使用することができる.
Takeaways(要点)
生成AIのためのこれらのデザインパターンは,単なるテンプレートではなく,明日のインテリジェントシステムが成長するためのフレームワークである.
我々が探求と革新を続けるにつれ,我々が選択するアーキテクチャが,能力だけでなく,我々が創造するAIのアイデンティティそのものを定義することになるのは明らかである.
このリストは決して最終的なものではなく,生成AIのパターンやユースケースが広がるにつれて,このスペースも発展していくだろう.
本記事(※訳注:「Generative AI Design Patterns: A Comprehensive Guide」のこと)は,Tomasz Tunguzが発表した「AI Design Patterns」にインスパイアされたものである.
まとめ
Tomasz Tunguzの「AI Design Patterns」の日本語訳を紹介しました.
AIのデザインパターンは,AIアプリケーションを開発する際に参考になることがわかりました.
AIのプログラミング言語「C++/Python言語」を学べるおすすめのWebサイトを知りたいあなたはこちらからどうぞ.
独学が難しいあなたは,AIを学べるオンラインプログラミングスクール3社で自分に合うスクールを見つけましょう.後悔はさせません!
国内・海外のAIエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ. こういった悩みにお答えします. こういった私が解説していきます. 国内・海外のAIエンジニアのおすすめ求人サイト(転職エージェント)を紹介します. AIエンジニアになるためには,主にC++/Pytho ... 続きを見る
国内・海外のAIエンジニアのおすすめ求人サイト【転職エージェント】【C++/Python言語】
国内・海外のプロンプトエンジニアのおすすめ求人サイトを知りたいあなたはこちらからどうぞ.
{kind=link}